

The CandyShop benchmark is an independent, reproducible test of open-source security scanners. I run 12 tools from five categories — SAST, DAST, SCA, container scanning, and IaC — against 6 intentionally vulnerable applications (OWASP Juice Shop, Broken Crystals, Altoro Mutual, vulnpy, DVWA, and WebGoat).
Each tool runs in its default configuration inside Docker, with no custom rules or tuning. The result: 10,047 total findings, of which 654 were confirmed as true positives through multi-tool consensus. This page reports the raw numbers, F-measure accuracy scores, and per-target breakdowns.

Key Findings#
1. Your base image matters more than your code#
DVWA’s PHP/Apache image produced 3,672 container findings (Grype + Trivy combined). Juice Shop’s Node.js image: 271.
Same tools, same configuration — the only variable is the base image. If your container scans are drowning you in noise, that’s where to look first.

2. More findings does not mean better detection#
Grype reported 5,046 findings across all 6 targets — the highest count from any tool. The vast majority came from base image OS packages, not application-level flaws. npm audit found 99 findings total, but 9 were critical and 46 were high. Look at severity distribution, not totals.
3. No single scanner catches everything#
The best performer (Trivy , F1=0.783) detected 66.2% of the consensus-confirmed vulnerabilities. That means even with the top-ranked tool, over a third of the known issues go undetected. Running multiple tools from different categories is the only way to approach full coverage.
4. Container scanners and SCA tools barely overlap#
Trivy and Grype scan the full container image (OS packages + app dependencies). npm audit and pip-audit only look at application-level manifests. On Juice Shop, Trivy found 135 issues and npm audit found 56, with very little overlap. You need both to get reasonable coverage.
5. Unauthenticated DAST barely scratches the surface#
ZAP consistently found 5-20 issues per target, mostly medium or lower severity. Without login credentials, ZAP only tests what an anonymous visitor can reach. The gap between 13 findings on Juice Shop and 20 on DVWA says more about how deep the login wall sits than about actual vulnerability counts.
6. IaC scanning catches what nothing else does#
Checkov flagged Dockerfile misconfigurations across 3 targets (Juice Shop, vulnpy, DVWA). Running containers as root, skipping health checks — these aren’t “vulnerabilities” in the traditional sense, but they’re real security problems that SAST, SCA, and DAST tools all ignore.

Which Open-Source Security Tool Is Most Accurate?#
Out of 10,047 total findings, 654 were confirmed as true positives through multi-tool consensus. The table below ranks each tool by F-measure (F1 score) — the metric that balances precision (are the findings real?) with recall (does the tool catch known issues?).
Trivy leads with an F1 of 0.783, followed by FindSecBugs (0.707) and OpenGrep (0.645). All tools achieved perfect precision under the consensus model, so the ranking is driven entirely by recall — how much of the known vulnerability set each tool detected.
| Tool | Avg F1 | Precision | Recall | TP | FP | CWEs |
|---|---|---|---|---|---|---|
| Trivy | 0.783 | 1.000 | 0.662 | 309 | 0 | 25 |
| FindSecBugs | 0.707 | 1.000 | 0.571 | 62 | 0 | 7 |
| OpenGrep | 0.645 | 1.000 | 0.490 | 109 | 0 | 13 |
| Bandit | 0.625 | 1.000 | 0.455 | 10 | 0 | 4 |
| Grype | 0.528 | 1.000 | 0.382 | 92 | 0 | 5 |
| Dependency-Check | 0.400 | 1.000 | 0.263 | 27 | 0 | 10 |
| npm audit | 0.394 | 1.000 | 0.246 | 19 | 0 | 10 |
| OWASP ZAP | 0.260 | 1.000 | 0.164 | 20 | 0 | 6 |
| Nuclei | 0.090 | 1.000 | 0.048 | 3 | 0 | 0 |
| NodeJsScan | 0.077 | 1.000 | 0.040 | 3 | 0 | 1 |
How Do Different Scanner Categories Compare?#
F1 scores rank tools by detection accuracy, but they hide an important tradeoff: a tool can have high recall but drown you in noise, or produce clean output but miss most vulnerabilities. The scatter plots below map both dimensions for each tool category, loosely inspired by the OWASP Benchmark scorecard format. Top-right corner is the sweet spot: high recall and high signal.

How to read these charts:
- F-Measure chart (above) ranks all 10 tools by F1 score. Precision is 1.000 for all tools under the consensus model, so the real differentiator is recall — what fraction of ground-truth vulnerabilities each tool detected.
- Category scatter plots position each tool by recall (Y-axis) and signal rate (X-axis: TP / Total Findings). Comparing within category makes more sense than across — a DAST tool finding runtime issues shouldn’t be penalized for not matching SAST detections.
- pip-audit and Checkov aren’t listed because neither had findings confirmed through multi-tool consensus. pip-audit’s dependency findings didn’t overlap with container scanner results at the CWE level, and Checkov’s IaC misconfigurations are unique to that category.
SAST Tools#
FindSecBugs has the highest signal rate (32.3%) despite scanning only 2 Java targets, and leads recall among SAST tools at 57.1%. OpenGrep sits at 49.0% recall and 23.9% signal — solid on both axes.
Bandit has 45.5% recall but low signal (11.5%) because many of its findings are informational. NodeJsScan has 21.4% signal but only detected 3 confirmed TPs across 2 targets.
Container Scanners#
Trivy has much higher recall (66.2% vs Grype ’s 38.2%), but both have single-digit signal rates. Trivy produced 3,854 findings to surface 309 TPs; Grype produced 5,046 for 92 TPs. This is just how container scanning works — base image vulnerabilities generate the bulk of the noise.
SCA Tools#
Dependency-Check and npm audit land in almost the same spot. Dep-Check edges ahead on recall (26.3% vs 24.6%) because it covers Java + JavaScript while npm audit is JavaScript-only. Both hover around 19% signal rates.
DAST Tools#
ZAP beats Nuclei on both axes. ZAP’s 24.1% signal rate is competitive with SAST tools, but its recall (16.4%) suffers under the consensus model — many runtime findings simply can’t be confirmed by static tools. Nuclei found only 3 confirmed TPs across all targets.
IaC Scanning#
Checkov is the only IaC tool in the benchmark. It flagged Dockerfile misconfigurations in 3 targets (Juice Shop, vulnpy, DVWA) — running containers as root, missing health checks, using latest tags.
These don’t show up in the F-measure or scatter plots because IaC misconfigurations don’t map to CWEs and can’t be confirmed through multi-tool consensus. Still, they’re real security risks that nothing else in the benchmark picks up.
How Many Vulnerabilities Did Each Tool Find?#
The heatmap below shows total findings per tool per target. Darker red means more findings. Click any target name for detailed observations.
| Tool | Juice Shop | Broken Crystals | Altoro Mutual | vulnpy | DVWA | WebGoat | Total |
|---|---|---|---|---|---|---|---|
| Grype | 136 | 2,111 | 62 | 144 | 2,097 | 496 | 5,046 |
| Trivy | 135 | 1,555 | 50 | 136 | 1,575 | 403 | 3,854 |
| OpenGrep | 70 | 42 | 46 | 12 | 100 | 186 | 456 |
| FindSecBugs | — | — | 54 | — | — | 138 | 192 |
| Dep-Check | 0 | 66 | 23 | 0 | 1 | 47 | 137 |
| npm audit | 56 | 43 | — | — | — | — | 99 |
| Bandit | — | — | — | 87 | — | — | 87 |
| ZAP | 13 | 5 | 17 | 14 | 20 | 14 | 83 |
| Nuclei | 14 | 12 | 12 | 5 | 10 | 4 | 57 |
| Checkov | 3 | 0 | 0 | 2 | 3 | 0 | 8 |
| pip-audit | — | — | — | 14 | — | — | 14 |
| NodeJsScan | 1 | 13 | — | — | — | — | 14 |
— = tool not applicable to this target's language/framework. Color scale: 0–10 11–50 51–200 201–500 501–1000 1000+
OWASP Juice Shop — 428 total findings across 8 tools
- OpenGrep found 70 issues with 38 at high severity — the only SAST tool to flag high-severity vulnerabilities on Juice Shop.
- Grype and Trivy reported nearly identical totals (136 vs 135) with similar severity distributions, which is reassuring — the two container scanners largely agree.
- npm audit found 7 critical and 31 high-severity dependency vulnerabilities.
Broken Crystals — 3,847 total findings across 8 tools
- Grype produced 2,111 findings — the heaviest base image in the benchmark, with 30 critical and 511 high-severity issues.
- Trivy hit 1,555 findings. The bloated base image explains the jump from Juice Shop’s 135.
- OpenGrep found 42 issues (26 high severity), while NodeJsScan caught 13 including 10 high-severity findings (hardcoded credentials and eval injection).
- Dependency-Check found 66 issues versus zero on Juice Shop — richer dependency trees give it more to work with.
- ZAP found only 5 issues despite 20+ vulnerability types in the target. Without authentication, DAST tools just can’t reach enough of the attack surface.
Altoro Mutual — 264 total findings across 7 tools
- FindSecBugs led with 54 findings, including 10 SQL injection, 3 path traversal, and 1 XXE. This is the only target where a Java-specific SAST tool outperformed container scanners.
- OpenGrep found 46 issues (13 high, 33 medium), picking up source-level patterns that FindSecBugs missed.
- Trivy reported 50 container findings including 5 critical CVEs in the Java runtime layer.
- ZAP found 17 DAST issues — its best result across all targets. Altoro Mutual’s simpler architecture is easier to crawl.
vulnpy — 414 total findings across 8 tools
- Bandit is the only Python-specific SAST scanner in the benchmark. It found 87 informational issues — mostly
eval(),exec(), andsubprocessusage. - Trivy found 136 container vulnerabilities, 107 of them low severity. The Python base image has a moderate vulnerability surface.
- pip-audit found 14 medium-severity issues — a clean, focused set compared to the container scanning noise.
- Interesting coincidence: ZAP and pip-audit both returned 14 findings, from completely different angles (runtime vs dependency analysis).
DVWA — 3,806 total findings across 7 tools (noisiest target)
- By far the noisiest target. Grype alone reported 2,097 findings and Trivy added 1,575. The PHP/Apache base image is a CVE magnet — 327 critical findings from Grype.
- Nuclei found a critical-severity issue here — the only critical from any DAST tool across all 6 targets. An exposed admin panel / known vulnerable endpoint.
- Dependency-Check found only 1 medium-severity issue. PHP/Composer gets much less SCA coverage than npm or Maven.
WebGoat — 1,288 total findings across 7 tools
- OpenGrep found 186 issues — the highest SAST count in the benchmark. The Java/Spring codebase triggered 44 high-severity and 142 medium-severity findings.
- FindSecBugs found 138 issues, including 14 SQL injection, 19 path traversal, and 14 Spring CSRF findings. Its bytecode analysis catches patterns that source-level scanners miss.
- Grype (496) and Trivy (403) had similar severity distributions here too — container scanners agree consistently.
- Dependency-Check had its best result here with 47 issues. Java/Maven is the ecosystem it handles best.
What Tools and Targets Are in the Benchmark?#
Tools Tested#
The CandyShop benchmark tests 12 open-source tools across five categories: SAST (OpenGrep, NodeJsScan, Bandit, FindSecBugs), DAST (OWASP ZAP, Nuclei), SCA (npm audit, pip-audit, OWASP Dependency-Check), container scanning (Trivy, Grype), and IaC (Checkov). All use open-source licenses (Apache 2.0, MIT, LGPL, GPL) — no commercial scanners, no vendor agreements needed.
| Category | Tools Tested |
|---|---|
| SAST | OpenGrep, NodeJsScan, Bandit, FindSecBugs |
| DAST | OWASP ZAP, Nuclei |
| SCA | npm audit, pip-audit, OWASP Dependency-Check |
| Container | Trivy, Grype |
| IaC | Checkov |
Test Targets#
6 intentionally vulnerable applications spanning Node.js, Java, Python, and PHP:
| Target | Stack | Vulnerabilities | Notes |
|---|---|---|---|
| Juice Shop | Node.js/Express/Angular | 100+ challenges | Most widely used vulnerable app |
| Broken Crystals | Node.js/TypeScript | 40+ types | JWT flaws, XXE, business logic |
| Altoro Mutual | J2EE | Classic web vulns | SQL injection, XSS, path traversal |
| vulnpy | Python/Flask | 13 categories | Python-specific scanner testing |
| DVWA | PHP/MariaDB | Adjustable levels | Classic training ground |
| WebGoat | Java/Spring | Guided lessons | OWASP teaching application |
All targets run in Docker containers via Docker Compose. Each scanned in default configuration with no custom rules or tuning.
How Is the Benchmark Methodology Designed?#
Environment Setup#
All 6 target applications run in Docker containers orchestrated via Docker Compose. Each target is scanned in its default configuration — no custom rules, no tuning. This is what you’d see on day one of integrating these tools.

Tool Selection Criteria#
Every tool in the benchmark meets three requirements:
- Open-source license (Apache 2.0, MIT, LGPL, GPL, or similar). No commercial tools, no freemium tiers, no “community editions” with half the features stripped out.
- Active maintenance — last commit within the past 12 months.
- CLI-driven — can run headless in a CI pipeline without a GUI.
How Is Ground Truth Established?#
Ground truth is the hard part of any benchmark like this. I use a multi-tool consensus model: when 2 or more tools from different categories flag the same CWE in the same file or endpoint, it counts as a confirmed true positive.
Single-tool findings are counted but not confirmed — they may be true positives that only one tool detects, or false positives. The ground truth set contains 152 entries across all 6 targets.
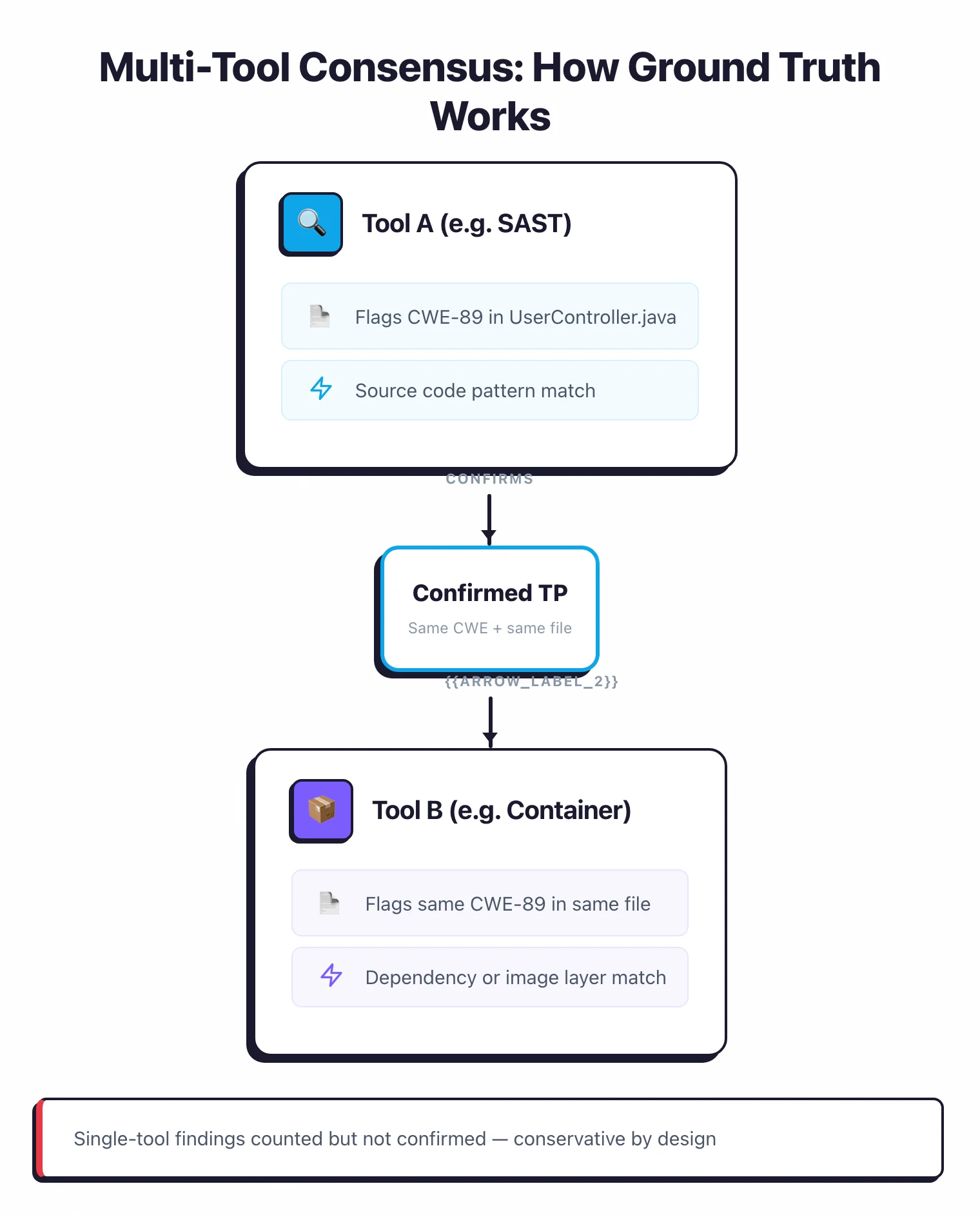
This approach is deliberately conservative. It undercounts true positives — a real vulnerability found by only one tool gets excluded — but it avoids inflating accuracy numbers with unverified findings. The tradeoff is intentional: I’d rather understate accuracy than overstate it.
How Is F-Measure Calculated?#
F-measure (also called F1 score) is the harmonic mean of precision and recall. For each tool, I calculate:
- Precision = TP / (TP + FP) — how many of the tool’s confirmed findings are real
- Recall = TP / (TP + FN) — how many of the known ground-truth issues the tool detected
- F1 Score = 2 * (Precision * Recall) / (Precision + Recall)
Under the consensus model, precision is 1.000 for all tools (by definition — if a tool’s finding was confirmed by another tool, it’s a true positive). The differentiator is recall: how much of the ground truth each tool covers.
A tool with an F1 of 0.783 (Trivy) detected 66.2% of known vulnerabilities, while a tool with 0.090 (Nuclei) caught under 5%.
Related guides: