

In late 2023, a team at Nanyang Technological University released PentestGPT . It was clunky.
It needed a human at the keyboard for every command. But it proved an LLM could reason about attack paths.
Two and a half years later, not much about that world still looks the same.
PentAGI has 14,700+ GitHub stars and orchestrates four sub-agents inside Docker sandboxes. XBOW ’s autonomous agent sits at #1 on HackerOne ’s global leaderboard with 1,060+ validated submissions.
Google’s Big Sleep found the first AI-discovered zero-day in production software — a SQLite buffer underflow that OSS-Fuzz had been missing for years. Anthropic’s Mythos then found thousands of high-severity vulnerabilities across every major OS and browser, and Anthropic decided it was too capable to ship broadly.
For this AppSec Santa research, I dug into 39+ open-source AI pentesting agents, read 8 academic benchmarks, and tracked every commercial company in the space from seed-stage startups to the two new unicorns.
What follows is a technical look at how these agents actually work, and the honest gap between what the press releases say and what the benchmarks measure.
The short version
- The field: AI pentesting agents are LLM-driven systems that run recon, vulnerability scanning, exploitation, and reporting autonomously. As of April 2026, there are 39+ open-source projects spanning 6 architecture patterns.
- Multi-agent wins: Hierarchical and specialized agent teams outperform single-agent approaches by 4.3× (HPTSA). Fine-tuned mid-scale models like xOffense (Qwen3-32B) hit 79.17% sub-task completion, beating both GPT-4 and Llama 3 baselines.
- Lab-to-real gap: GPT-4 exploits 87% of one-day CVEs when given advisory descriptions, but only 13% of real CVEs in CVE-Bench and nearly 0% of hard HackTheBox challenges.
- Breakout moments: XBOW's autonomous agent took #1 on HackerOne in June 2025, later publishing 1,060+ valid submissions. ARTEMIS (December 2025) beat 9 of 10 human pentesters on a live 8,000-host enterprise network at $18/hour.
- Tipping point: In April 2026, Anthropic's Mythos Preview found thousands of high-severity vulnerabilities in every major OS and browser — and Anthropic judged it too capable to release broadly.
Key findings#
What are AI pentesting agents?#
An AI pentesting agent is a piece of software that uses a large language model to do the work a human penetration tester would normally do: recon, vulnerability scanning, exploitation, and writing up what it found.
The word “agent” matters. A copilot only advises; an agent takes actions.
It runs the commands, reads the output, and decides what to try next. Most of them do this inside a ReAct (Reasoning-Acting) loop: look at the state, pick an action, run it, observe the result, repeat.
As of April 2026, at least 39 open-source projects fit this description, ranging from thin wrappers around a single LLM call to multi-agent swarms with their own vector databases.
Scanners like Nessus or Nuclei run a fixed set of checks. An agent reads the output of those checks and forms a hypothesis.
When a hypothesis fails, it tries a different one. That’s the whole difference: a checklist versus thinking through a problem.
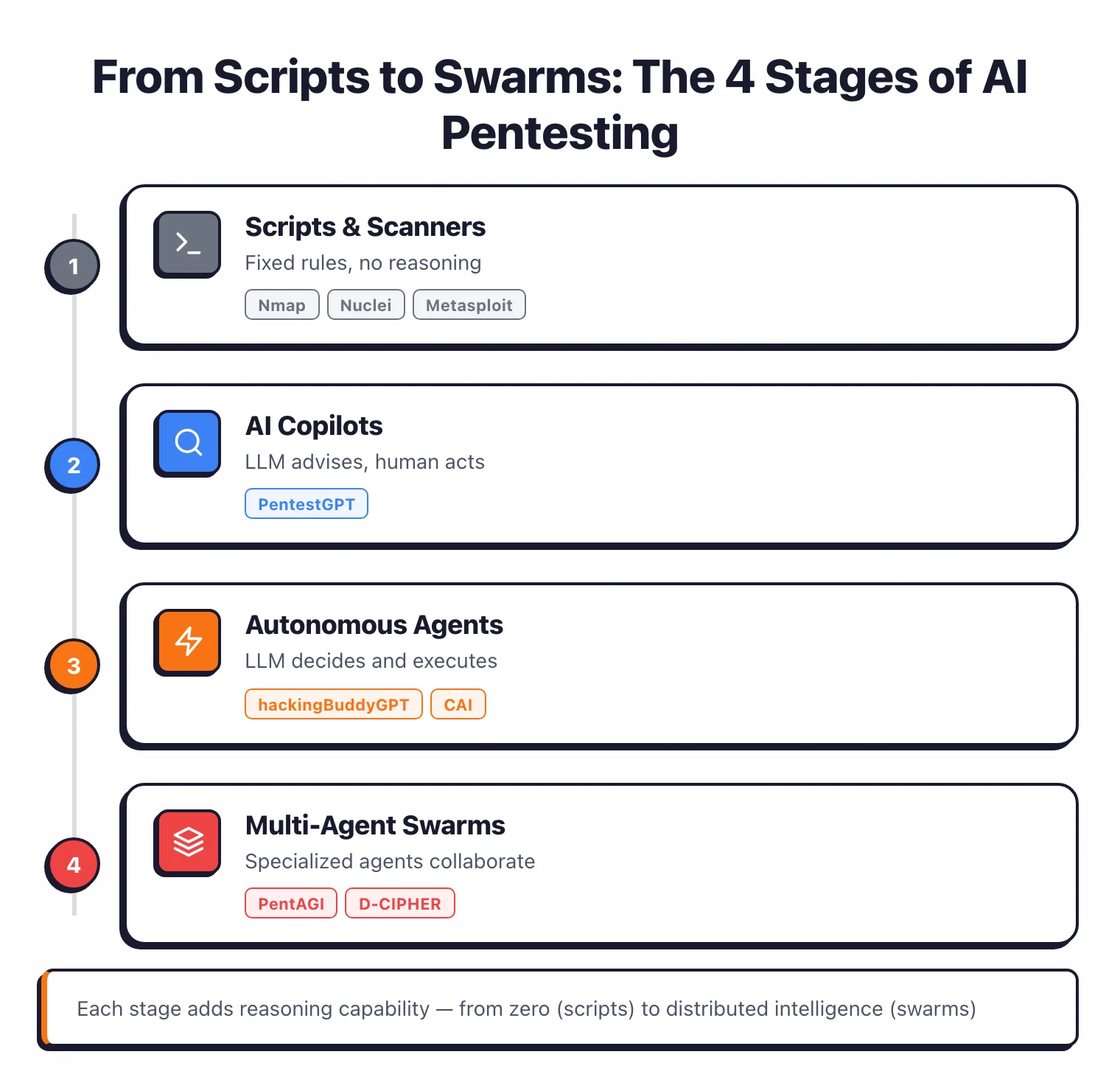
How we got here#
Pre-2023 was the scanner era. Nmap runs port scans, Nuclei checks known CVEs, Metasploit fires exploit modules.
No reasoning, no adaptation. If anything creative needed to happen, a human did it.
2023 was the copilot year. PentestGPT could read scan output and suggest the next step, but the human still typed every command. The model didn’t touch the keyboard.
In 2024-2025, agents started running commands themselves. hackingBuddyGPT and CAI execute shell commands inside sandboxes, read the output, and decide what to do next.
Sometimes a human approves each step. Often not.
2025-2026 is the swarm era. Specialized agents work in parallel: a planner picks the strategy, a recon agent maps the attack surface, an exploit agent tries to break things, a reporter writes it up. PentAGI , VulnBot , and D-CIPHER are the tools that opened this door.
How they differ from Metasploit and Cobalt Strike#
Traditional frameworks are playbook executors. You pick a module, you point it at a target, it does the thing. That’s effective for known exploits but it can’t reason about anything new.
AI agents are reasoning engines with tool access. They read scan output the way a human does, form a guess about what’s exploitable, and try approaches that don’t exist in any playbook.
When an exploit fails, they look at the error and try something different. No scanner does that.
The tradeoffs are real. Agents are less reliable than battle-tested exploit code, they cost more per action, and they hallucinate. But they handle situations nobody wrote a module for.
How do AI pentesting agents work?#
After reading 39+ open-source projects and their papers, I counted six distinct architecture patterns. Each one trades something off — usually simplicity for capability, or capability for cost.
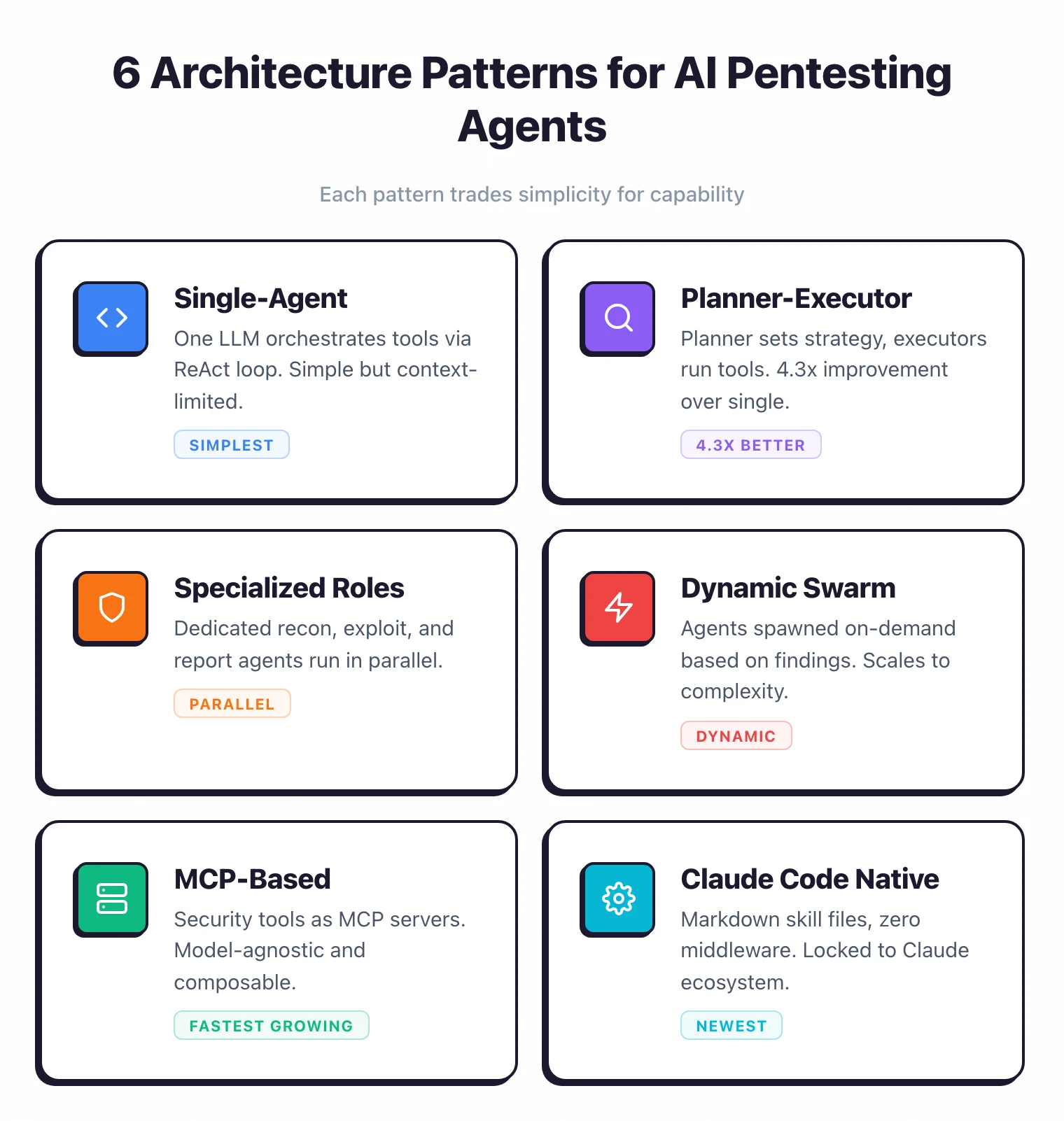
Pattern 1: Single-agent (ReAct loop)#
The simplest thing that works. One LLM gets the objective, generates an action, runs it, reads the result, and loops until the task is solved or the context window runs out.
That context window is also the biggest problem. A single nmap scan can spit out thousands of lines, and once those lines push the earlier findings out of context, the agent forgets what it knew.
Examples of this pattern: PentestGPT , hackingBuddyGPT , AutoPentest , RapidPen . Easy to build, easy to debug, predictable.
hackingBuddyGPT shows how minimal it can get — about 50 lines of Python, no framework, no database, no middleware. It connects over SSH, sends commands, and feeds output back.
PentestEval (December 2025) looked at all the single-agent frameworks it could find and concluded they “failed almost entirely” on end-to-end pipelines. That’s the ceiling of this design.
Pro tip: If you're building your own agent, start with hackingBuddyGPT. It's ~50 lines of Python and makes the ReAct loop easy to read. Fork it, swap the prompt, and you've shipped a working research agent in an afternoon.
Pattern 2: Multi-agent planner-executor#
The planner handles strategy, the executors handle tactics. The planner never touches a tool itself, it just decides what should happen next and hands off the work.
This solves the context problem. Each executor gets a focused subtask with a fresh context window.
It runs the tools, collects the results, and reports back. The planner reads the summaries (not the raw output) and picks the next subtask.
The main projects here are VulnBot , CHECKMATE , and HPTSA . They each bring one interesting idea.
VulnBot’s Penetration Task Graph is a directed graph where nodes are pentesting tasks and edges are dependencies. The planner tracks which attacks depend on which recon results and runs the independent branches in parallel.
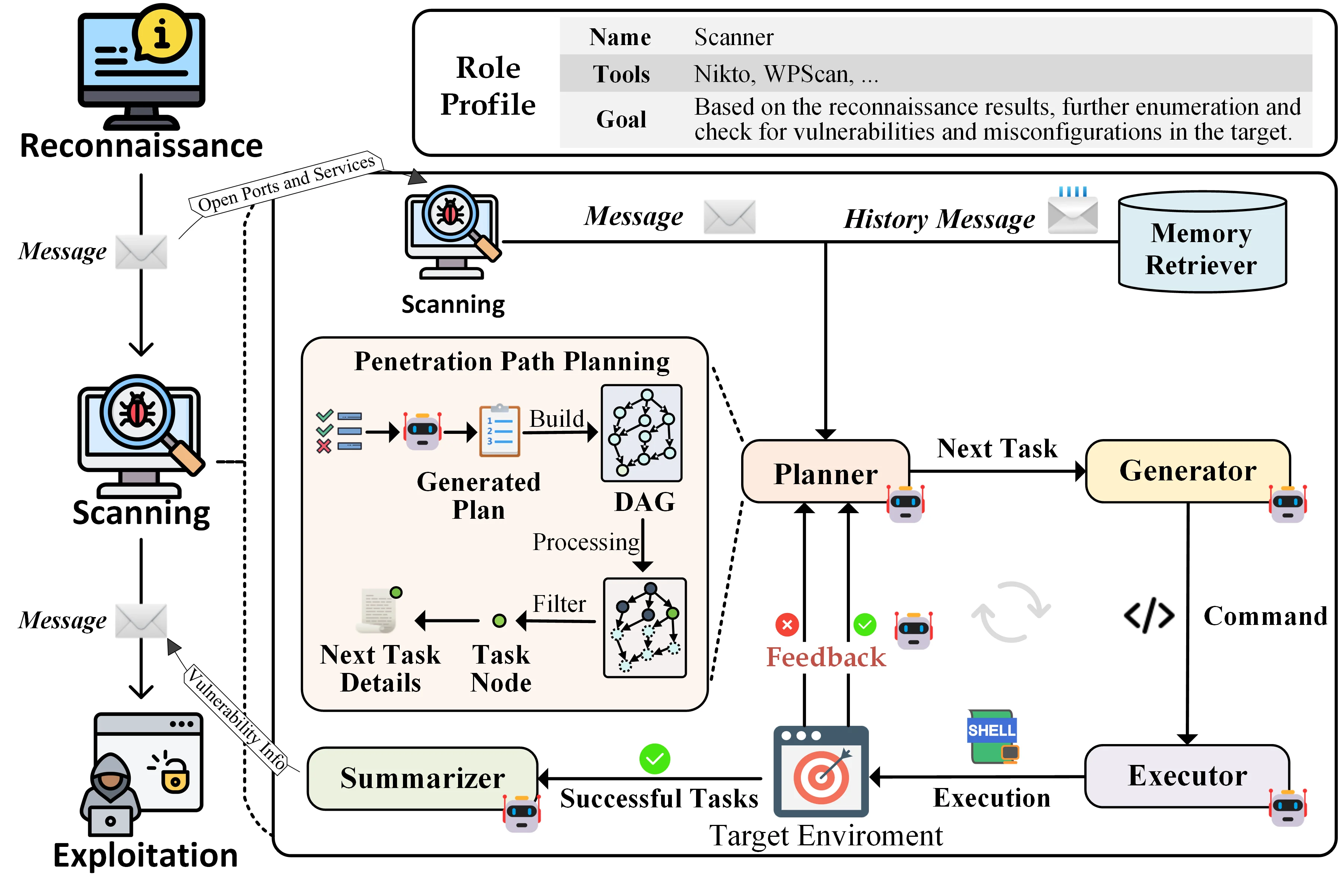
CHECKMATE goes a different direction. Instead of trusting the LLM to plan, it has the LLM write a PDDL domain description and hands that to a classical planner. The classical planner finds the optimal sequence, and the executor agents carry each step out.
That hybrid beats Claude Code’s native agent by more than 20% on success rate, and it does it more than 50% faster and cheaper. The lesson: don’t ask the LLM to do the thing it’s bad at (long-horizon planning) when an algorithm from the 1970s already solved it.
HPTSA’s results drive the pattern home. On a benchmark of 14 real-world vulnerabilities, its hierarchical teams were 4.3 times better than single-agent frameworks — 42% pass@5 and 18% pass@1. The architecture beats the monolith, consistently.

Pattern 3: Multi-agent with specialized roles#
This pattern gives each agent a fixed domain. One for reconnaissance, one for exploitation, one for reporting. They run at the same time and share what they find through a central state or message bus.
The orchestrator spawns them with domain-specific prompts, their own tool access, and sometimes their own knowledge bases. When the recon agent finds something, it kicks the vulnerability agent into gear, which kicks off the exploit agent.
Three notable implementations:
- PentAGI — Four sub-agents: Searcher (OSINT), Coder (script generation), Installer (dependency management), Pentester (offensive operations). Written in Go with a React frontend. Uses PostgreSQL with pgvector for semantic memory.
- Zen-AI-Pentest — Multi-agent state machine with dedicated Recon, Vulnerability, Exploit, and Report agents. Integrates 72+ security tools. FastAPI backend with WebSocket real-time updates.
- BlacksmithAI — Hierarchical agents: Orchestrator coordinating Recon, Scan/Enum, Vuln Analysis, Exploit, and Post-Exploitation agents.
The upside is parallelism and genuine domain expertise per agent. The downside is brittle orchestration and failure cascades: if the recon agent misses an open service, nothing downstream ever tests it. And you’re paying for multiple LLM calls in parallel, so the bill adds up faster.
Pattern 4: Dynamic swarm#
Here the agent count isn’t fixed. New agents spawn based on what earlier agents discovered, and the swarm grows or shrinks to match the attack surface.
Two examples worth looking at. Pentest Swarm AI is a 5-agent Go-native swarm with an orchestrator and four specialists, all running on Claude, integrating 7 native Go security tools (subfinder, httpx, nuclei, naabu, katana, dnsx, gau).
D-CIPHER adds an auto-prompter — a third agent that rewrites the instructions of the other agents when it sees failure patterns. That’s the part that makes it interesting; most frameworks just retry.
The numbers back it up. D-CIPHER holds state of the art across three benchmarks: 22.0% on NYU CTF, 22.5% on CyBench, 44.0% on HackTheBox. It also solves 65% more MITRE ATT&CK techniques than the single-agent baselines it was tested against.
Pattern 5: MCP-based (Model Context Protocol)#
These agents don’t build their own framework at all. They wrap security tools as MCP servers (Anthropic’s standard interface for connecting LLMs to external tools) and let whatever LLM client you want — Claude Desktop, Cursor, a custom host — do the reasoning.
It’s a different philosophy. Instead of writing your own agent loop, you treat nmap, nuclei, metasploit, and Burp as MCP endpoints with typed input/output schemas and let the model orchestrate them itself. No custom agent code to maintain.
The prominent projects here are HexStrike AI with 150+ tools exposed as MCP endpoints, and AutoPentest-AI with 68+ tools plus 109 WSTG tests and 31 PortSwigger guides.
There’s also PentestMCP , a library of MCP server implementations for nmap, curl, nuclei, and metasploit — tested with o3 and Gemini 2.5 Flash, presented at BSidesPDX 2025.
The tradeoff is direct: you’re composable and model-agnostic, but the quality of the reasoning is entirely on the client. There’s no custom planning logic to lean on. If the LLM is bad at it, the MCP server can’t save you.
MCP is also the fastest-growing pattern in the field. Early 2026 saw an explosion of these projects — partly because they’re cheap to build, partly because they slot straight into Claude Code, Claude Desktop, or any MCP client.
Pattern 6: Claude Code native#
The newest pattern. There’s no custom framework at all — agents are defined as markdown skill files that configure Claude Code’s built-in agent infrastructure. You write a .md file, drop it in the right folder, and Claude Code runs it.
Three examples:
Raptor — built by Gadi Evron, Daniel Cuthbert, Thomas Dullien (Halvar Flake), Michael Bargury, and John Cartwright. A CLAUDE.md-based configuration with rules, sub-agents, and skills, plus AFL fuzzing and CodeQL integration.

- Transilience Community Tools — 23 skills, 8 agents, 2 tool integrations. Achieved 100% (104/104) on a published CTF benchmark from 89.4% baseline.
- Claude Bug Bounty — 8 skill domains, 13 slash commands, 7 agents, 21 tools. Integrates with Burp Suite and HackerOne/Bugcrowd APIs.
Zero middleware means fast iteration. Changing agent behavior is editing a markdown file, not deploying code.
The downside is obvious: you’re locked into the Claude ecosystem, and your performance ceiling is whatever Claude Code’s agent runtime supports today.
How agents chain security tools#
The architecture varies, but the tool chain pattern is nearly identical across projects:
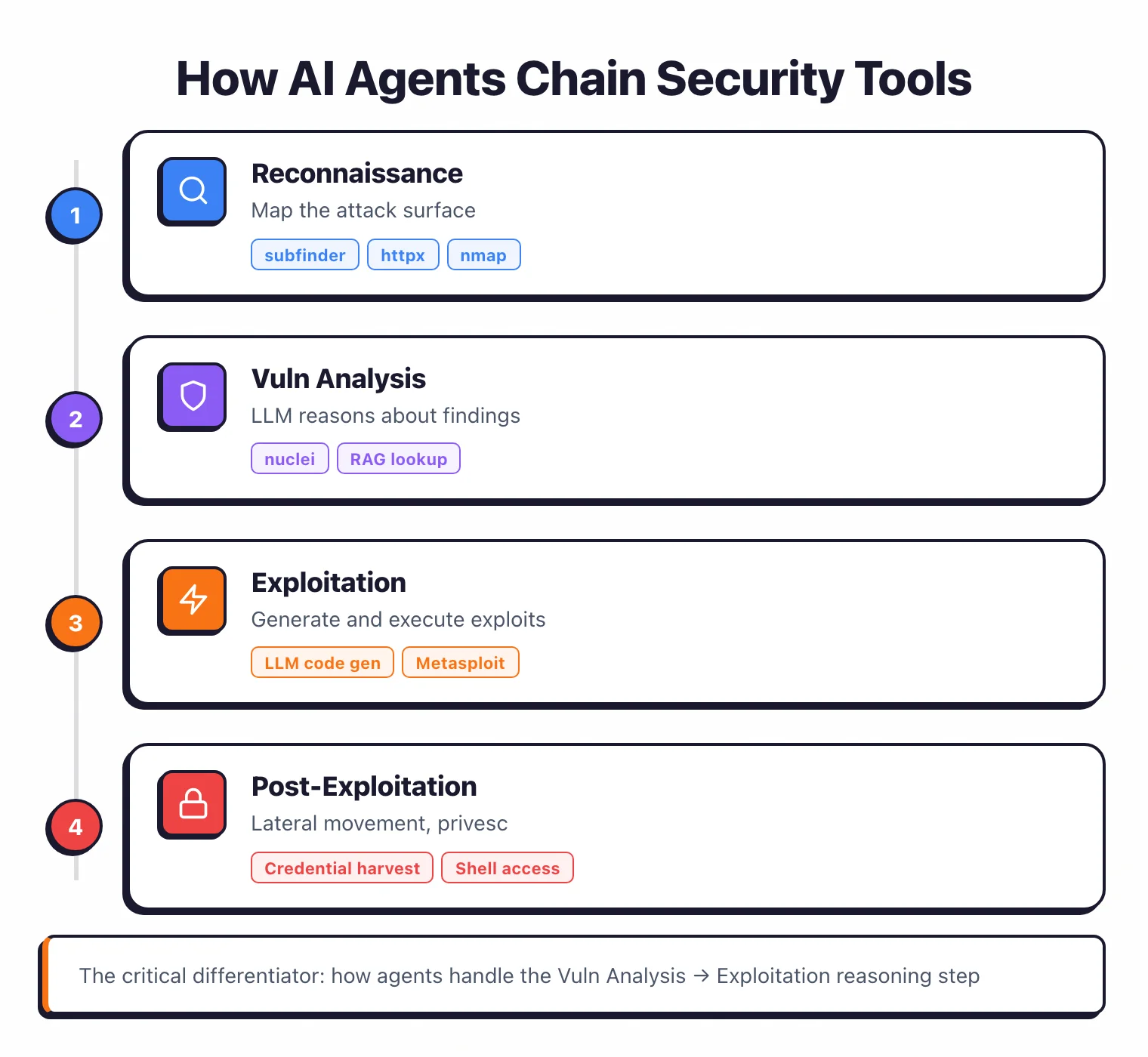
Phase 1 — Reconnaissance: Target → subfinder (subdomain enumeration) → httpx (HTTP probing) → nmap (port scanning) → Technology fingerprinting
Phase 2 — Vulnerability analysis: Scan results → nuclei (known CVE checks) → LLM analysis of service versions → RAG lookup against exploit databases → Vulnerability prioritization
Phase 3 — Exploitation: Prioritized vulns → LLM generates exploit code or selects Metasploit module → Sandboxed execution → Output interpretation → Success/failure decision → Retry with modified approach
Phase 4 — Post-exploitation (if applicable): Shell access → Credential harvesting → Lateral movement → Privilege escalation → Data exfiltration mapping
Where these designs actually differ is the Phase 2-to-3 transition — the reasoning step where the agent picks a vulnerability and decides how to exploit it.
Single-agent systems feed everything into one context window and hope the LLM can keep it straight.
Multi-agent systems split the strategy (planner) from the execution (executors), and it’s consistently the better approach.
How do AI agents handle long pentesting sessions?#
This is the hardest problem in the whole field, and nobody has fully solved it.
A real penetration test produces gigabytes of scan output.
The agent needs to track dozens of services, remember which ones it’s already poked, and build multi-step attack chains where the first thing it found three hours ago still matters. LLMs aren’t designed for any of that.
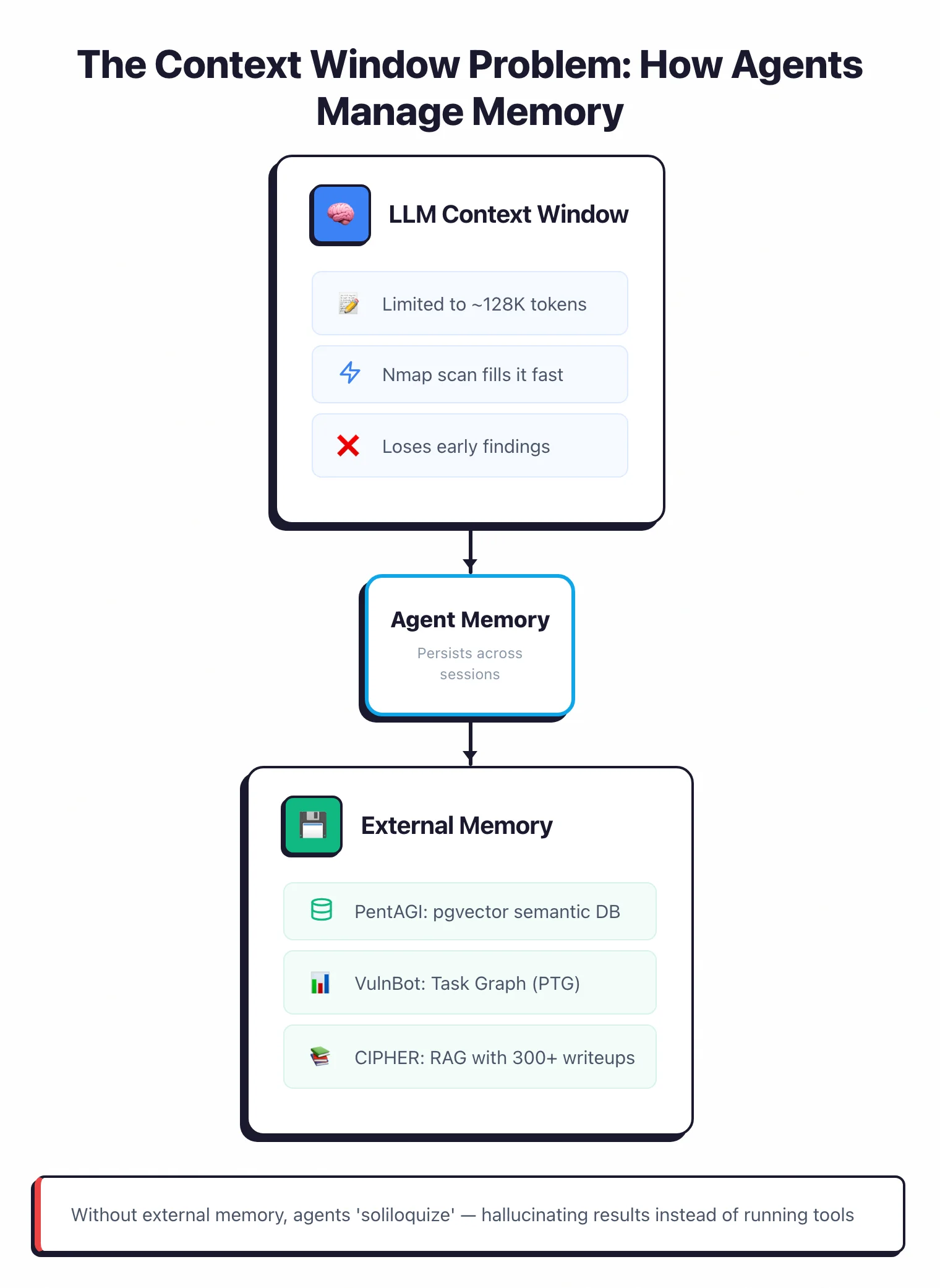
PentAGI takes the semantic memory approach.
It runs PostgreSQL with pgvector and stores findings as vector embeddings.
When the exploit agent needs to recall which ports were open, it doesn’t search raw nmap output — it queries the vector database.
That decouples the agent’s long-term memory from whatever fits in the LLM’s context window at the moment.
VulnBot does it differently.
Its Penetration Task Graph is a directed graph where nodes are tasks and edges are dependencies.
The graph persists across the whole session and tracks what’s been tried, what worked, and what’s still waiting on upstream results.
When a new vulnerability shows up, the graph automatically spawns downstream exploitation tasks.
A third approach is RAG augmentation. Several agents inject pentesting knowledge at decision time by retrieving it from an offline corpus.
CIPHER was trained on 300+ high-quality pentesting writeups and it outperforms Llama 3 70B even though it’s a smaller model.
RapidPen maintains an exploit knowledge base that the agent queries whenever it runs into a specific service version.
Then there’s the soliloquizing problem.
The EnIGMA paper (ICML 2025) documented a failure mode where agents stop actually running commands and start imagining the output instead.
The agent “pretends” a command succeeded, builds on the imaginary result, and ends up in a self-referential loop where nothing it says corresponds to reality.
It’s not hallucination in the usual sense — the agent looks like it’s working. It just isn’t.
Which LLM works best for penetration testing?#
The data is messier than the press releases make it sound.
GPT-4 and GPT-4o are still the most-tested models. Fang et al.’s landmark 2024 study showed GPT-4 exploiting 87% of one-day CVEs when it had the advisory description in context.
Every other model it tested scored 0%. Every scanner also scored 0%. Most open-source agents default to GPT-4o for this reason.
Claude powers Pentest Swarm AI natively and is the backbone of everything in the Claude Code-native pattern.
Anthropic’s Mythos Preview is the current frontier of what any model can do at this task, but it isn’t publicly available.
The interesting part is fine-tuned open-source.
xOffense took Qwen3-32B, fine-tuned it on offensive security data, and hit 79.17% sub-task completion — beating both VulnBot and PentestGPT running on larger frontier models.
CIPHER did the same thing at smaller scale and outperformed Llama 3 70B and Qwen1.5 72B despite being the smaller model.
Domain adaptation matters more than raw scale. That was not the obvious bet two years ago.
Local models via Ollama are the privacy play. Nothing leaves your network, which matters for sensitive engagements.
But capability drops, sometimes a lot. CAI supports 300+ model backends including Ollama so you can pick your tradeoff explicitly.
Tool catalog: 39+ open-source projects#
I tracked down every notable open-source AI pentesting agent I could find as of April 2026. Here’s the full list, sorted into tiers by maturity and documentation.

Tier 1: Major autonomous agents#
The most-starred, most-documented, or most-benchmarked projects. If you’re evaluating something today, start here.
PentAGI — The most-starred AI pentest project on GitHub (~14,700 stars). Written in Go with a React frontend.
Four sub-agents (Searcher, Coder, Installer, Pentester) orchestrated by a central coordinator. Docker-sandboxed execution.
LLM-agnostic via LiteLLM (12+ providers). PostgreSQL + pgvector for semantic memory. MIT license.

Shannon (Keygraph) — White-box pentester that combines source code analysis with browser automation and CLI tools. Scored 96.15% (100/104 exploits) on a cleaned, hint-free white-box variant of the XBOW benchmark. Keygraph itself notes the result is not directly comparable to XBOW’s reported black-box numbers (~85% on the original benchmark) — but the score establishes Shannon as the highest publicly disclosed open-source result in its category.
Focuses on web app and API testing: injection, auth bypass, SSRF, XSS. Generates proof-of-concept exploits for every finding.
PentestGPT — The pioneer (~12,500 stars). Three self-interacting modules: Reasoning, Generation, Parsing. Each maintains its own LLM session to manage context.
Published at USENIX Security 2024 with Distinguished Artifact Award. 228.6% task-completion increase over GPT-3.5 baseline. Human-in-the-loop — advises next steps, human executes.
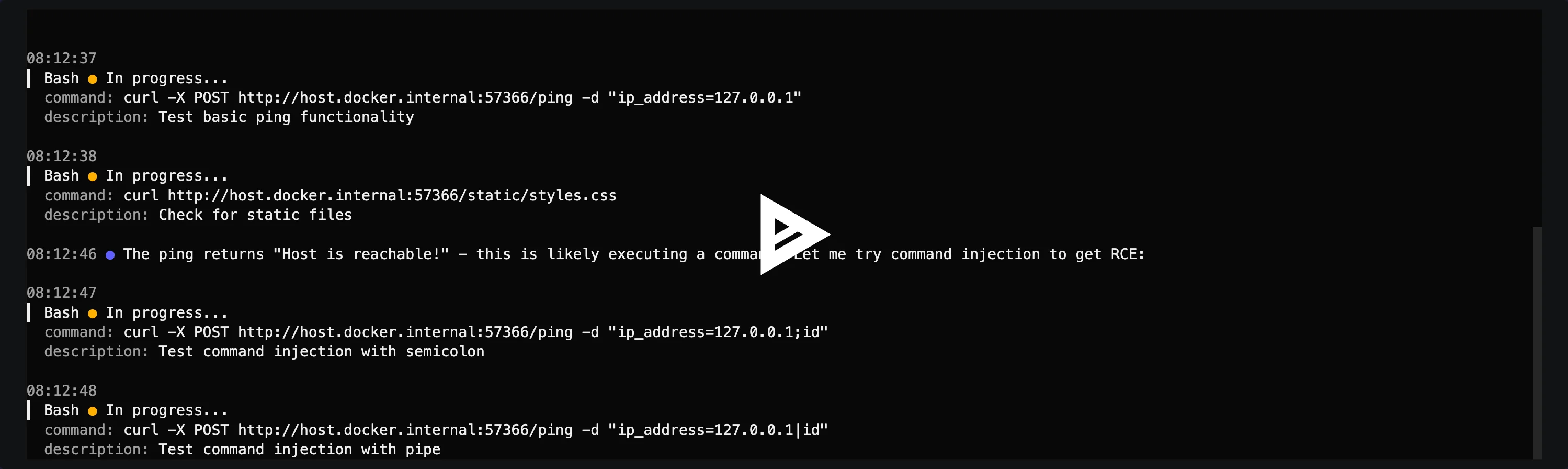
Strix — Agentic platform with HTTP proxy manipulation, browser automation, terminal sessions, and a Python exploit environment. CI/CD integration via GitHub Actions. Apache 2.0.
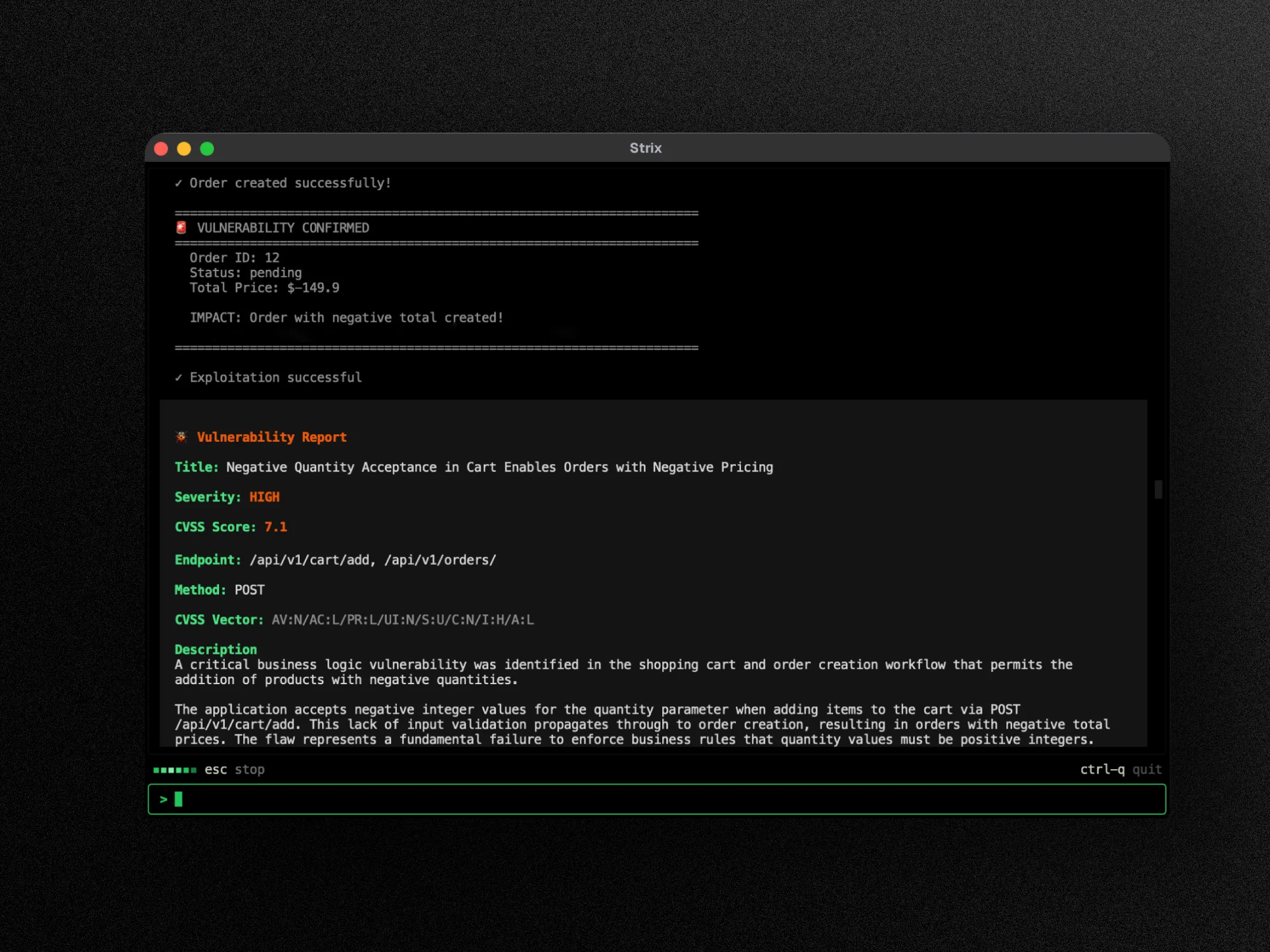
In comparative testing, Strix was one of only two tools (with CAI) that delivered actionable results against a banking application. I cover its setup and OWASP Top 10 coverage in my Strix review .
CAI (Cybersecurity AI) — Lightweight extensible framework supporting 300+ model backends. Built-in tools for reconnaissance, exploitation, and privilege escalation.
Self-hosted LLM support for air-gapped environments. Used by hundreds of organizations for HackTheBox CTFs, bug bounties, and real-world assessments.
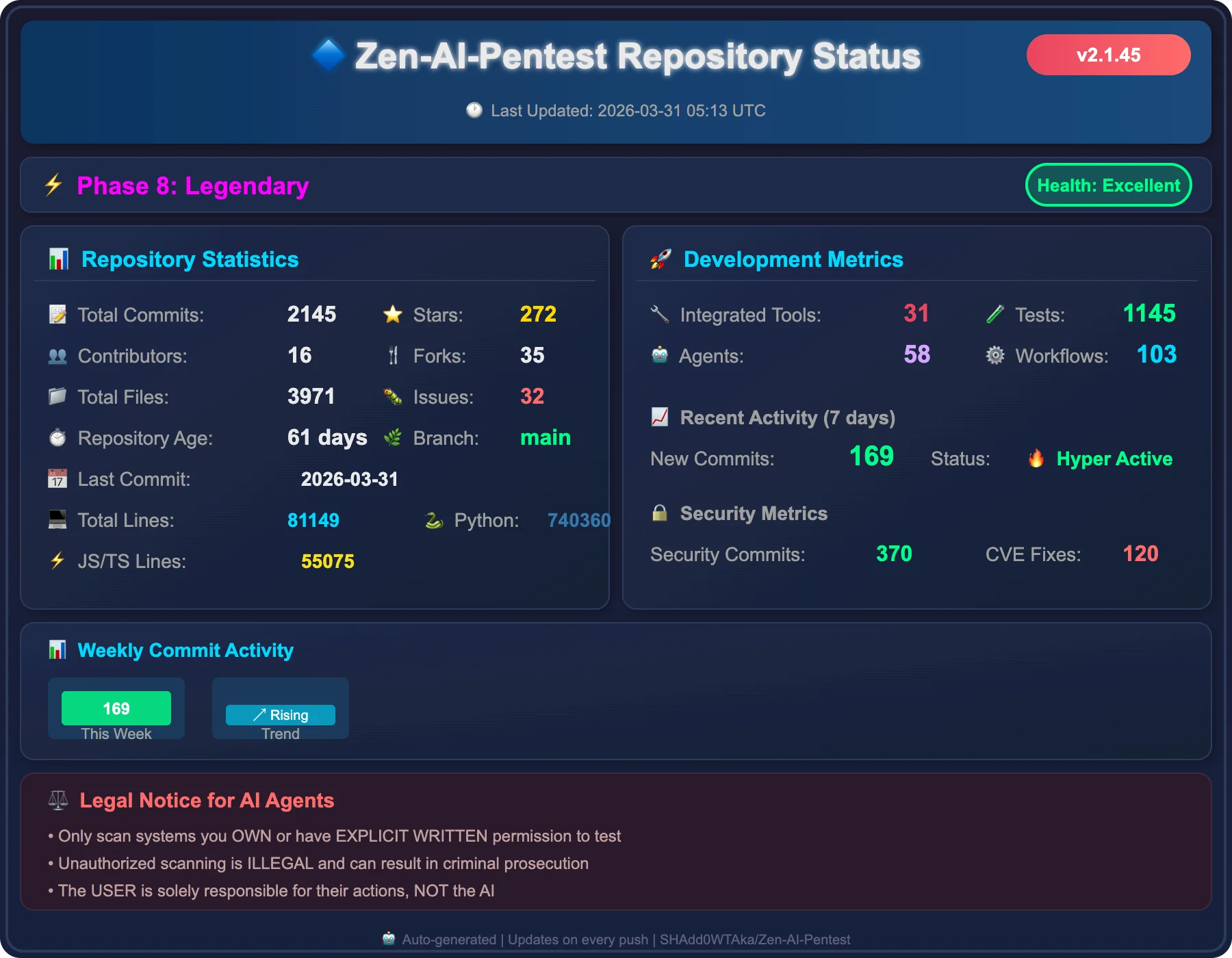
Zen-AI-Pentest — Multi-agent state machine launched February 2026. Integrates 72+ security tools across 9 categories: Network, Web, Active Directory, OSINT, Secrets, Wireless, Brute Force, Code Analysis, Cloud/Container.
Four specialized agents (Recon, Vulnerability, Exploit, Report) with FastAPI backend and WebSocket updates. CVSS (Common Vulnerability Scoring System) / EPSS (Exploit Prediction Scoring System) scoring. Available as a GitHub Action.
Tier 2: Specialized and emerging agents#
VulnBot — Academic multi-agent system with 5 core modules: Planner, Memory Retriever, Generator, Executor, Summarizer. Its Penetration Task Graph (PTG) manages task dependencies.
Three modes: automatic, semi-automatic, human-involved. Outperforms baseline GPT-4 and Llama 3 on automated pentesting tasks.
HackSynth — Dual-module architecture: Planner generates commands, Summarizer processes feedback. Published with a 200-challenge benchmark (PicoCTF + OverTheWire). GPT-4o significantly outperformed all other tested models.
hackingBuddyGPT — Research-grade minimal framework. Approximately 50 lines of Python for the base example.
SSH and local shell support. Designed for extensibility by security researchers, not production use.
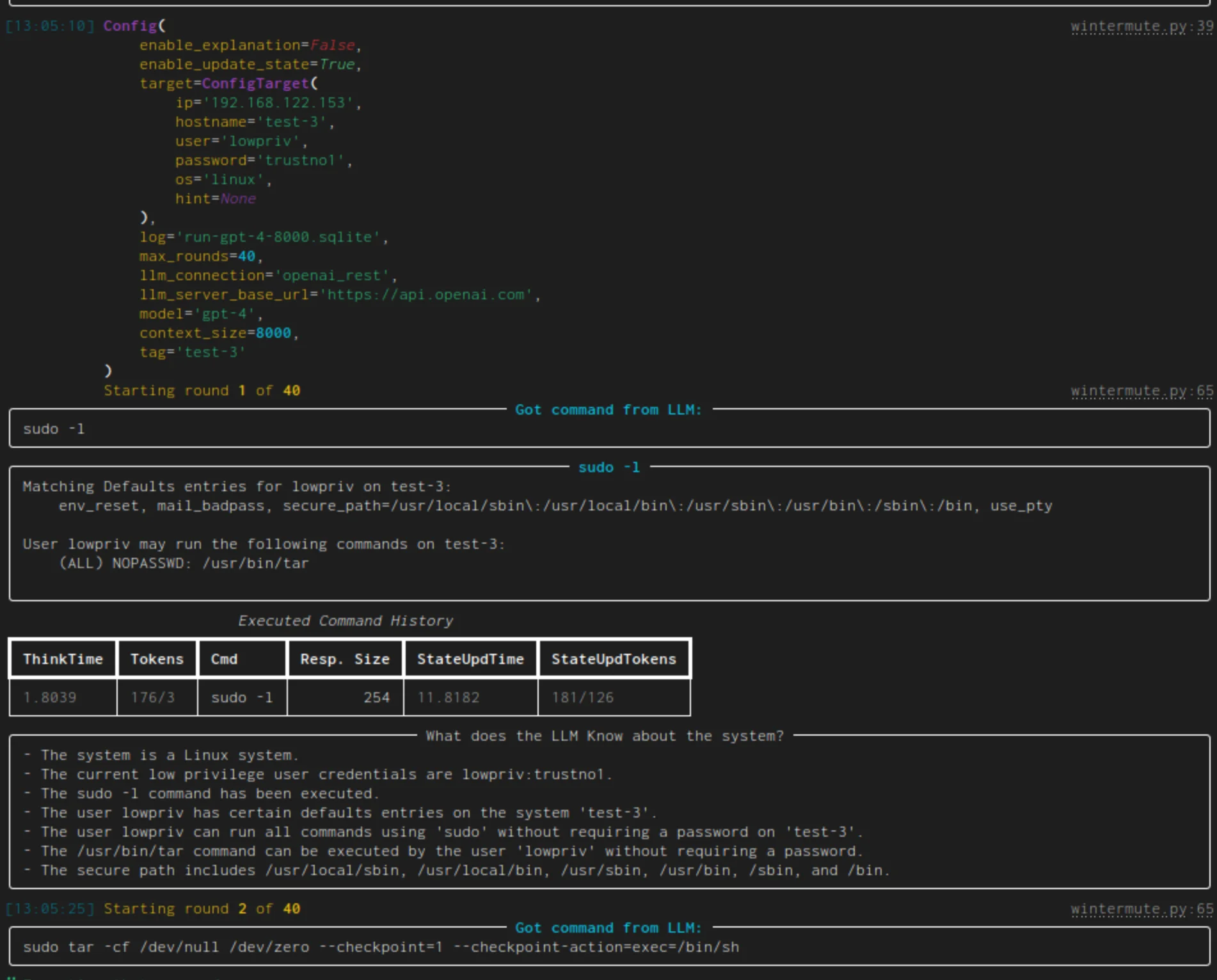
ARACNE — Fully autonomous SSH service pentester using multi-LLM architecture (separate Planner, Interpreter, Summarizer). 60% success rate against ShelLM autonomous defender. 57.58% on OverTheWire Bandit CTF. When successful, completed objectives in fewer than 5 actions on average.
Pentest Swarm AI — Go-native 5-agent swarm using Claude API. Orchestrator coordinates 4 specialist agents with ReAct reasoning.
Integrates 7 native Go security tools (subfinder, httpx, nuclei, naabu, katana, dnsx, gau). Bug bounty, continuous monitoring, and CTF modes. CVSS v3.1 scoring.
BlacksmithAI — Hierarchical multi-agent system launched March 2026. Orchestrator coordinates Recon, Scan/Enum, Vuln Analysis, Exploit, and Post-Exploitation agents.
Docker-based tooling. Web and terminal interfaces. OpenRouter, VLLM, and custom provider support. GPL-3.0.
PentestAgent (GH05TCREW) — Multi-agent with MCP extensibility. Prebuilt attack playbooks.
Built-in tools: terminal, browser, notes, web search, and spawn_mcp_agent. Persistent knowledge via loot/notes.json. Fully autonomous with hierarchical child agents.
NeuroSploit — AI-driven agents in isolated Kali Linux containers per scan. Covers 100 vulnerability types.
React web interface. MIT license. V3 currently active, though encountered execution issues in third-party evaluation.
AutoPentest — LangChain-based GPT-4o agent for black-box pentesting. Tested on HackTheBox machines.
Completed 15-25% of subtasks, slightly outperforming manual ChatGPT interaction. Total experiment cost: $96.20.
Tier 3: MCP-based tools#
HexStrike AI — 150+ cybersecurity tools exposed as MCP endpoints. Compatible with any MCP-capable LLM client (Claude, GPT, Copilot). Automated pentesting, vulnerability discovery, and bug bounty automation.
AutoPentest-AI (bhavsec) — MCP server with 68+ tools, 109 WSTG tests, 31 PortSwigger technique guides. Playwright integration via MCP.
Docker container with 27 pre-installed security tools. Quality assurance subagent.
PentestMCP — Academic library of MCP server implementations for nmap, curl, nuclei, and metasploit. Tested with o3, Gemini 2.5 Flash, and other models. Presented at BSidesPDX 2025.
pentest-ai (0xSteph) — MCP server + Python agents with 150+ security tools. Exploit chaining, PoC validation, professional reporting. Compatible with Claude, GPT, Copilot, and Windsurf.
pentest-ai-agents (0xSteph) — 28 Claude Code subagents with no middleware or custom framework. Full pentest lifecycle from scoping to reporting, including defensive detection rules.
Raptor — Claude Code-based system created by Gadi Evron, Daniel Cuthbert, Thomas Dullien (Halvar Flake), Michael Bargury, and John Cartwright. Claude.md-based configuration with rules, sub-agents, and skills.
AFL fuzzing and CodeQL integration. Agentic commands: /scan, /fuzz, /web, /agentic, /codeql.
Tier 4: Vulnerability discovery tools#
VulnHuntr (Protect AI) — LLM-powered static analysis that traces full call chains from user input to server output. Python-only.
Covers 7 vulnerability types: file overwrite, SSRF, XSS, IDOR, SQLi, RCE, LFI. Found 12+ zero-days in large open-source Python projects. Supports Claude, GPT, and Ollama.
VulHunt (Binarly) — Binary analysis framework with Lua detection rules and MCP server integration. Analyzes POSIX executables and UEFI firmware without source code.
Community edition is open source. Launched March 2026.
Nebula — AI-assisted CLI terminal tool for recon, note-taking, and vulnerability analysis guidance. Supports OpenAI, Llama-3.1-8B, Mistral-7B, and DeepSeek-R1. Human-driven with AI assistance, not autonomous.
AI-OPS — AI assistant for penetration testing focused on open-source LLMs. Copilot-style: human-in-the-loop for all actions.
Tier 5: DARPA AIxCC open-sourced cyber reasoning systems#
All 7 finalist CRS systems from DARPA’s AI Cyber Challenge were released as open source after the August 2025 finals:
Atlantis (Team Atlanta — 1st place, $4M prize) — Georgia Tech, Samsung Research, KAIST, POSTECH. Multi-agent reinforcement learning combined with LLMs and symbolic analysis.
Dominated the scoreboard with roughly the combined score of 2nd and 3rd place.
Buttercup (Trail of Bits — 2nd place, $3M prize) — Four components: Vulnerability Discovery, Contextual Analysis, Patch Generation (7 distinct AI agents), Validation. Covers 20 of DARPA’s Top 25 Most Dangerous CWEs.
Designed to run on a laptop.
Theori (3rd place, $1.5M prize) — Full CRS open-sourced as part of AIxCC.
ARTIPHISHELL (Shellphish) — Built on the angr binary analysis framework. Components across github.com/angr, github.com/shellphish, and github.com/mechaphish.
The remaining finalists (all_you_need_is_a_fuzzing_brain, 42-b3yond-6ug, Lacrosse) are also open-source.
Catalog summary#
Across all five tiers, the open-source AI pentesting space now spans 39+ active projects. Here’s the breakdown by tier and what they’re best at:
| Tier | Count | Best for |
|---|---|---|
| Tier 1 — Major autonomous agents | 6 | Production use, most documentation and benchmarks |
| Tier 2 — Specialized and emerging | 9 | Research, experimentation, niche use cases |
| Tier 3 — MCP-based | 6 | Fastest iteration, model-agnostic workflows |
| Tier 4 — Vulnerability discovery | 4 | Source and binary analysis for zero-day hunting |
| Tier 5 — DARPA AIxCC CRS systems | 7 | Research reference implementations, academic validation |
Most of these projects are less than 18 months old.
Stars, documentation depth, and maintenance frequency vary widely — pick Tier 1 for anything approaching production, Tier 2 for experiments, and Tier 3/4 if you want to stitch together your own pipeline.
How effective are AI pentesting agents?#
Quick answer: AI pentesting agents achieve 87% success on one-day CVEs when given advisory descriptions (Fang et al., 2024), but drop to 13% on realistic CVE-Bench conditions and near-zero on hard HackTheBox challenges.
Multi-agent architectures outperform single-agent ones by 4.3× (HPTSA), and fine-tuned mid-scale models like xOffense (Qwen3-32B) reach 79.17% sub-task completion, beating both GPT-4 and Llama 3 baselines.
Eight academic benchmarks now measure AI agents on offensive security tasks. I read all of them to answer a simple question: how capable are these things, really?

Benchmark framework overview#
| Benchmark | Venue | Tasks | Focus |
|---|---|---|---|
| CyBench | ICLR 2025 (Oral) | 40 pro-level CTF tasks | End-to-end CTF solving |
| NYU CTF Bench | NeurIPS 2024 | 200 challenges | Multi-domain offensive security |
| CVE-Bench | ICML 2025 (Spotlight) | 40 critical-severity CVEs | Real-world web app exploitation |
| AutoPenBench | arXiv 2024 | 33 tasks | Autonomous pentesting |
| PentestEval | arXiv 2025 | 346 tasks across 12 scenarios | Stage-by-stage pentesting |
| CAIBench | arXiv 2025 | 10,000+ instances | Meta-benchmark (5 categories) |
| CyberSecEval 1-4 | Meta | Progressive | Code safety + offensive operations |
| HackTheBox AI Range | HtB 2025 | Multi-difficulty | Real infrastructure targets |
Aggregated results#
| Benchmark context | Best agent | Success rate |
|---|---|---|
| One-day CVEs with advisory descriptions | GPT-4 | 87% |
| Sub-task completion with fine-tuned model | xOffense (Qwen3-32B) | 79.17% |
| Zero-day exploitation with multi-agent teams | HPTSA (GPT-4) | 42% pass@5 |
| HackTheBox challenges (multi-agent) | D-CIPHER | 44.0% |
| End-to-end pipeline | Best of 9 LLMs | 31% |
| Autonomous pentesting (no human) | GPT-4o | 21% |
| Real CVEs in sandbox | SOTA agent | 13% |
| CyBench pro-level CTF | Claude 3.5 Sonnet | Only tasks humans solve in <11 min |
| Hard HackTheBox challenges | All models | ~0% |
How big is the gap between lab benchmarks and real-world performance?#
This is the single most important finding in the whole field, and it’s the thing press coverage usually gets wrong.
The gap between sanitized academic conditions and real-world performance is enormous.
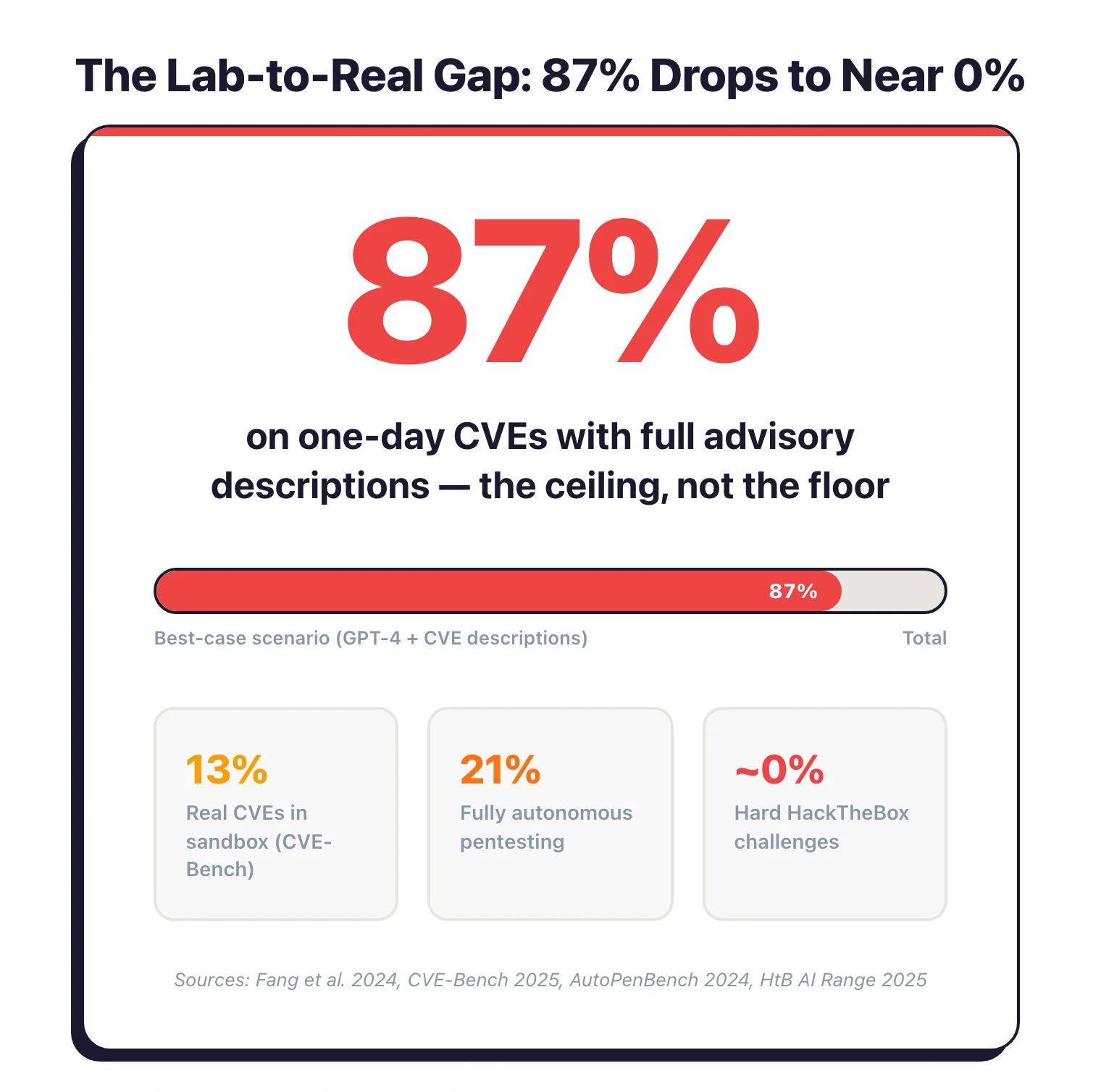
Give GPT-4 a one-day CVE along with its advisory description and it exploits 87% of them.
That’s the headline number everyone cites when they want to argue AI will replace pentesters.
Strip out the description and GPT-4 drops to 7%. Every other model and every scanner in the same test scored 0%.
Swap in CVE-Bench, which puts agents against 40 critical-severity CVEs in a framework designed to mimic real conditions, and the state of the art drops to 13%.
Move to actual infrastructure — HackTheBox’s AI Range — and every model tested hits near-perfect scores on Very Easy and Easy boxes.
Hard boxes, per the published results, “proved nearly impossible for current AI agents.”
AutoPenBench tried the fully autonomous version of the same question.
Without human guidance, agents solved 21% of tasks. With human hints along the way, the number jumped to 64%.
PentestEval tested 9 LLMs on 346 tasks and found end-to-end pipeline success was only 31%.
The paper concluded that all the fully autonomous agents “failed almost entirely.”
The pattern holds across every study: the more realistic the conditions, the worse the agents do.
The 87% number is the ceiling of ideal conditions, not the floor of practical capability. That’s the sentence to remember.
Note: When a vendor claims 87%+ on one-day CVEs, check whether the advisory description was in context. That single variable moves the number from 87% to 7%. It's the most common way pentesting AI numbers get misread.
Where AI beats humans (and where it doesn’t)#
The ARTEMIS study (December 2025) is the first head-to-head comparison I’ve seen on a real enterprise network.
The test environment was roughly 8,000 hosts across 12 subnets, all live.
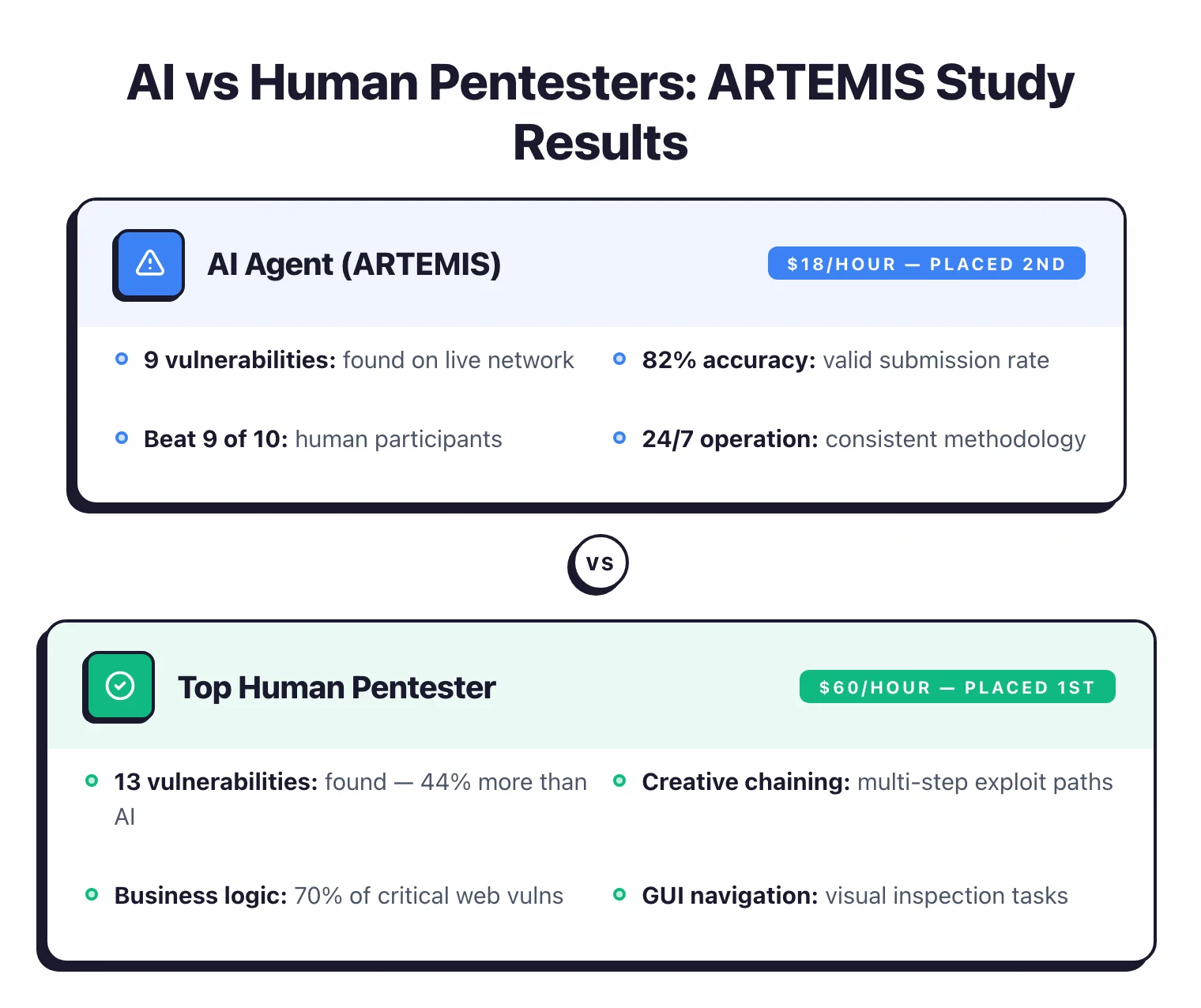
ARTEMIS placed second overall.
It found 9 valid vulnerabilities with an 82% submission accuracy and outperformed 9 of the 10 human pentesters in the study.
The top human pentester still won with 13 valid issues.
The delta wasn’t speed — ARTEMIS was faster — it was creative exploit chaining, validating weird edge cases, and spotting business logic flaws that the agent didn’t even register as bugs.
The cost numbers are where this gets interesting. ARTEMIS ran at roughly $18/hour. Professional pentesters bill at $60/hour or more.
So the AI is three times cheaper and already beats most humans in the room, even though it still loses to the best one.
What each side is good at breaks down roughly like this. AI wins on breadth, 24/7 uptime, consistent methodology, and speed on known vulnerability classes.
Humans win on creative exploit chaining, business logic, GUI-driven flows, and anything that requires imagining an attack nobody’s documented yet.
The paper drops one more number worth memorizing: 70% of critical web application vulnerabilities are business logic flaws.
No autonomous agent currently detects these reliably. That’s the actual moat.
Key Insight
70% of critical web vulnerabilities live in business logic — the one class no autonomous agent currently detects reliably. Speed, breadth, and known-CVE coverage are commoditizing. Creative intent-modeling is the part that still pays human rates.
What have AI pentesting agents actually found?#
Google Big Sleep: the first AI-discovered zero-day#
In November 2024, Google’s Project Zero and DeepMind published the “From Naptime to Big Sleep” post, disclosing their first real-world AI finding: an exploitable vulnerability discovered in early October and fixed the same day.
It was the first publicly disclosed AI-discovered exploitable vulnerability in production software.
A stack buffer underflow in SQLite, missed by both OSS-Fuzz and SQLite’s own extensive test suite. Fixed the same day, before any official release.
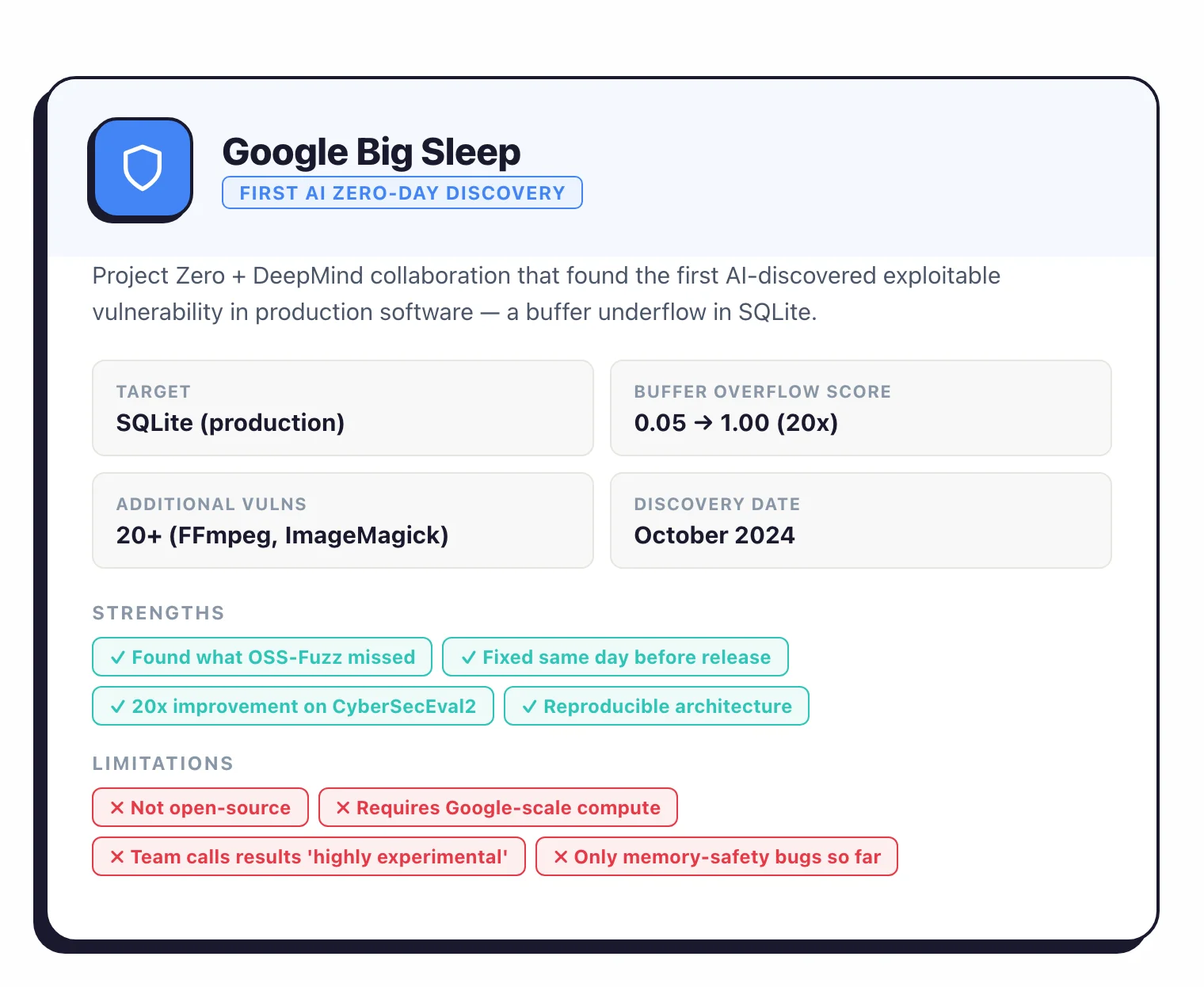
Big Sleep’s architecture is four components wired together: a Code Browser for navigating source, a Python sandbox for running test code, a debugger with AddressSanitizer to catch memory issues, and a Reporter that formats findings.
Google’s paper lists five design principles behind it: give the agent reasoning space, give it an interactive environment, give it specialized tools, make verification perfect, and use a good sampling strategy.
On Meta’s CyberSecEval2, Project Naptime scored 1.00 on buffer overflow detection, up from a 0.05 baseline. That’s a 20× improvement.
It also scored 0.76 on advanced memory corruption (up from 0.24).
By August 2025, Big Sleep had autonomously found 20 vulnerabilities in widely-used open-source software, mostly FFmpeg and ImageMagick.
Google announced those as the agent’s first batch of real-world finds outside the SQLite case.
XBOW: #1 on HackerOne#
XBOW — founded in 2024 by Oege de Moor, creator of GitHub Copilot and earlier founder of Semmle/CodeQL, and built with engineers from the original Copilot team — hit something genuinely unprecedented in June 2025: its autonomous agent took #1 on HackerOne ’s US leaderboard and reached the global top shortly after, outranking thousands of human bug bounty hunters.
The numbers: 1,060+ vulnerabilities submitted.
A 48-step exploit chain escalating a low-severity blind SSRF into full compromise.
XBOW also matched a principal pentester’s 40-hour manual assessment in 28 minutes.
Their own 104-challenge benchmark has emerged as a reference suite for the category, though Keygraph’s Shannon variant uses a cleaned, hint-free configuration that diverges from XBOW’s own evaluation conditions.
XBOW raised $237M total including a $120M Series C in March 2026, valuing the company above $1 billion.
Their “Pentest On-Demand” product compresses the traditional 35-100 day pentesting cycle into hours.
HackerOne platform-wide trends#
HackerOne’s 2025 report is the clearest public view of what AI is doing to bug bounties. The numbers:
- $81M paid in bounties in 2025 (+13% year-over-year)
- 210% jump in valid AI vulnerability reports
- 540% jump in prompt injection reports
- 560+ valid reports submitted by fully autonomous AI agents
- 1,121 customer programs now include AI in scope (+270% YoY)
- $3B in breach losses avoided; $15 saved for every $1 spent on bounties
Bugcrowd’s 2026 “Inside the Mind of a Hacker” report adds one more: 82% of hackers now use AI tools in their daily workflow. In 2023 that number was 64%.
Trend Micro AESIR#
Since mid-2025, Trend Micro’s AESIR platform has found 21 critical CVEs across NVIDIA, Tencent, MLflow, and MCP tooling .
It’s one of the clearest signs that AI-assisted vulnerability discovery works outside a research lab, against actively used commercial software, at commercial scale.
Tipping point: Anthropic Mythos and Project Glasswing#
Quick answer: Claude Mythos Preview is Anthropic’s frontier model announced April 7, 2026. It autonomously discovered thousands of high-severity vulnerabilities in every major operating system and web browser.
Standout finds include a 27-year-old OpenBSD flaw and a 16-year-old FFmpeg bug that automated tools had tested 5 million times without finding.
Anthropic judged it too dangerous for public release and limited access to 12 Project Glasswing launch partners plus 40+ additional critical-infrastructure organizations.
On April 7, 2026, Anthropic announced Claude Mythos Preview. Three days later I’m writing this — and I keep thinking about what it means that a frontier lab’s next model was judged too dangerous to release broadly.
What Mythos can do#
Mythos Preview is a general-purpose frontier model that happens to be exceptionally good at cybersecurity.
Anthropic used it to scan major codebases and it came back with thousands of high-severity vulnerabilities, including bugs in every major operating system and web browser.
Specific examples from Anthropic’s announcement: a 27-year-old flaw in OpenBSD that allowed remote crashes, a 16-year-old FFmpeg vulnerability that automated tools had tested 5 million times without finding, and chained Linux kernel bugs that enabled privilege escalation.
Anthropic’s framing was blunt:
“AI models have reached a level of coding capability where they can surpass all but the most skilled humans at finding and exploiting software vulnerabilities.” — Anthropic, April 2026

Why it’s not public#
Rather than a broad release, Anthropic limited access to the 12 Glasswing launch partners plus 40+ additional organizations that build or maintain critical software infrastructure.
The decision reflected a judgment that the offensive capabilities were too powerful for unrestricted access — a first for a general-purpose model release.
Project Glasswing#
Glasswing is Anthropic’s initiative to deploy Mythos defensively. The 12 launch partners are Anthropic, AWS, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorgan Chase, the Linux Foundation, Microsoft, NVIDIA, and Palo Alto Networks.
Anthropic also committed $100M in usage credits and $4M in direct donations to open-source security organizations.
The framing is defensive: find and fix vulnerabilities before attackers do. But the capability is inherently dual-use.
What this means for open-source#
If a frontier model can find vulnerabilities in every major OS and every major browser, the debate about whether AI can do offensive security is over. It can.
The real question is how quickly the open-source side closes the gap, and whether defensive uses will outpace offensive ones.
Look at how fast the curve is moving:
- 2024: DARPA AIxCC semifinals. AI systems detect 37% of synthetic vulnerabilities.
- 2025: DARPA AIxCC finals. Detection jumps to 86% in twelve months.
- 2025: XBOW reaches #1 on HackerOne’s global leaderboard.
- 2025: ARTEMIS beats 9 of 10 human pentesters on a live enterprise network.
- 2026: Mythos finds vulnerabilities in every major OS and browser.
Every one of those milestones would have sounded implausible twelve months before it happened.
Open-source agents today are bottlenecked by the models they can access, not by the agent architecture. When frontier model capabilities trickle down, everything in this article moves forward at the same time.
Key Insight
The open-source ceiling isn't the framework anymore — it's the base model. PentAGI, VulnBot, and HPTSA are already better architected than they need to be. The day a Mythos-class model becomes publicly available, every agent in this article jumps a tier at once.
Who are the commercial AI pentesting companies?#
The AI pentesting market has pulled in more than $665 million in disclosed VC funding. Two of those companies are now unicorns.
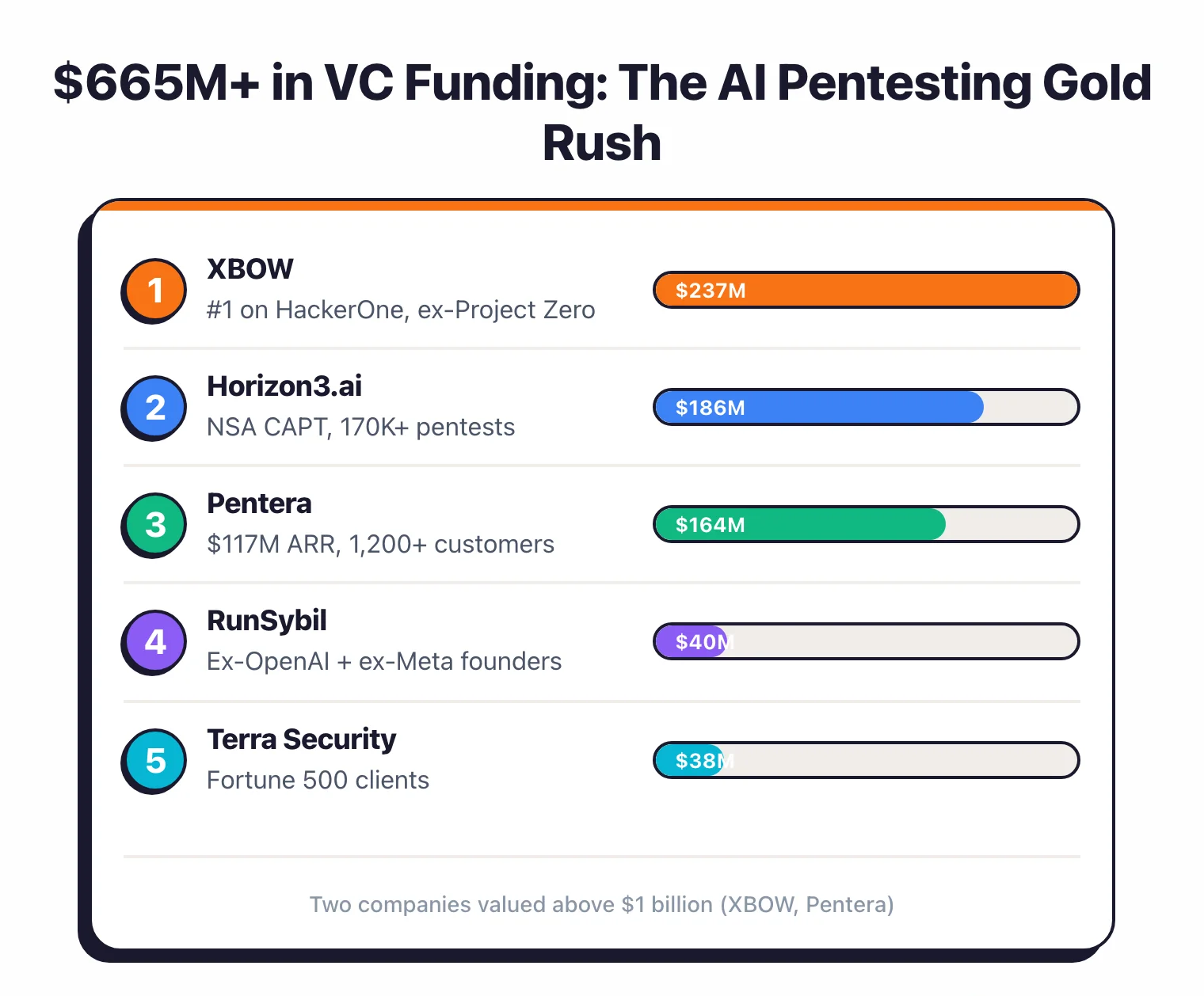
Funding map#
| Company | Total funding | Latest round | Valuation | Key differentiator |
|---|---|---|---|---|
| XBOW | $237M | Series C ($120M, March 2026) | $1B+ | #1 on HackerOne, 1,060+ vulns |
| Horizon3.ai | $186M | Series D ($100M, June 2025) | — | NSA CAPT program, 150K+ pentests |
| Pentera | $250M | Series D ($60M, March 2025) | $1B+ | ~$100M ARR, 1,200+ customers |
| RunSybil | $40M | Seed (March 2026) | — | Ex-OpenAI + ex-Meta Red Team founders |
| Terra Security | $38M | Series A ($30M, September 2025) | — | Fortune 500 clients |
| Hadrian | — | — | — | Nova agent, GigaOm ASM Leader (3 years) |
Market size#
The broader penetration testing market was valued at $2.74 billion in 2025 and is projected to reach $6.25-7.41 billion by 2033-34, with a compound annual growth rate of 11.6-12.5% (Straits Research, Fortune Business Insights).
The new category: Adversarial Exposure Validation#
The industry has folded breach and attack simulation, automated penetration testing, and automated red teaming into one category called Adversarial Exposure Validation. Key vendors in the space include Horizon3.ai, Pentera, Picus Security, Cymulate, FireCompass, and SafeBreach.
By 2027, Gartner projects 40% of organizations will run formal exposure validation programs, up from roughly 5% today.
By 2028, more than half of enterprises are expected to use AI security platforms at all. That adoption curve explains why the category exists.
Open-source versus commercial gap#
Commercial wins on the boring things that keep production running.
Continuous 24/7 testing, enterprise-grade reliability (Horizon3 has run 150,000+ pentests with zero downtime), compliance reporting, and remediation orchestration. None of that is technically hard. It’s organizationally hard, and open-source projects don’t usually have the team to pull it off.
Open-source wins on everything else. Transparency, full customization, no vendor lock-in, and the small matter of being free.
Shannon’s 96.15% on the XBOW benchmark lands in the same neighborhood as the best commercial results.
The direction everyone is moving is convergence. Trail of Bits open-sourced Buttercup. Every AIxCC finalist open-sourced their CRS.
The gap on raw capability is narrowing, fast. Enterprise reliability is the moat that remains, and it’s a real one.
AI pentesting timeline: 2023-2026#
How should defenders respond to AI pentesting agents?#
If you run an application security program, the benchmark data has specific implications for what you should be doing right now.
What these agents find fastest#
Pulling from aggregated benchmark results, AI agents are reliably effective at four things:
- Known CVEs in unpatched services. Agents match scan output to CVE databases with near-perfect accuracy whenever advisory descriptions are available.
- SSRF and injection flaws. Consistently the highest-performing vulnerability class across every benchmark.
- Misconfigured services. Default credentials, exposed admin panels, information disclosure.
- Standard web vulnerabilities. SQLi, XSS, and path traversal with known payloads.
What they still miss#
- Business logic flaws. 70% of critical web vulnerabilities are business logic issues, and detecting them requires understanding what the application is supposed to do, not just what it does.
- Complex multi-step chains. Agents struggle with exploitation paths that need 5+ steps and conditional branching.
- GUI-dependent vulnerabilities. Anything that requires visual inspection, drag-and-drop, or graphical interaction.
- Novel attack vectors. Actual zero-day discovery in production code remains rare. Big Sleep and XBOW are outliers, not the norm.
Recommended actions#
Patch faster. AI agents compress the window between CVE publication and exploitation dramatically.
As part of AppSec Santa’s ongoing AI security research , this is the single clearest trend I see in the data.
When GPT-4 can exploit 87% of CVEs given their descriptions, the time from disclosure to attack goes from days to minutes.
Assume continuous scanning. Commercial AI pentesting is moving toward always-on testing.
Your exposed services are being probed by somebody’s AI agent, whether you hired that agent or not.
Refocus human pentesters on business logic.
The highest-value work for humans is shifting away from “find the open port and the known CVE” (AI does that better and cheaper now) toward “understand the application’s business logic and find design flaws.” Pay them for the work only they can do.
Test your AI defenses against published benchmarks.
The lab-to-real gap means vendor claims should be verified against your actual environment before you put them on a critical path.
Limitations#
This analysis is built on published code, documentation, academic papers, and public benchmark results. I didn’t run any of these agents myself.
Here’s what that means for how much weight to give the conclusions.
GitHub stars aren’t a quality signal. They measure visibility and marketing.
PentAGI has 14,700+ stars, but that doesn’t mean it beats VulnBot’s academically validated Penetration Task Graph on real targets.
Not all benchmarks are created equal. CyBench (ICLR 2025 Oral) and CVE-Bench (ICML 2025 Spotlight) went through rigorous peer review.
Some GitHub projects cite their own self-reported numbers with no independent validation. I try to note which is which when it matters.
The field moves fast. New tools and papers show up weekly.
Projects I wrote about here may be abandoned, forked, or superseded by the time you read this. I used April 2026 as the cutoff.
Commercial tools are partially opaque by design. XBOW’s results are self-reported. Horizon3.ai’s NSA CAPT program outcomes come from Horizon3.ai’s own presentation.
Independent third-party evaluations of commercial tools are still rare.
Even the most realistic benchmarks are not production. ARTEMIS and HackTheBox AI Range both operate inside controlled environments with known boundaries.
Real pentesting targets have unpredictable configurations, weird network conditions, and active defenders who will make things worse on purpose. None of the benchmarks simulate that.
References#
All papers, tools, and data sources referenced in this analysis:
Foundational Papers:
- Deng, G. et al. “PentestGPT: An LLM-empowered Automatic Penetration Testing Tool.” USENIX Security 2024. arXiv:2308.06782
- Fang, R. et al. “LLM Agents Can Autonomously Exploit One-day Vulnerabilities.” 2024. arXiv:2404.08144
- Fang, R. et al. “Teams of LLM Agents Can Exploit Zero-Day Vulnerabilities.” 2024. arXiv:2406.01637
Agent Architectures:
- Shen, X. et al. “PentestAgent: Incorporating LLM Agents to Automated Penetration Testing.” AsiaCCS 2025. arXiv:2411.05185
- Nieponice, T. et al. “ARACNE: An LLM-Based Autonomous Shell Pentesting Agent.” 2025. arXiv:2502.18528
- Nakatani, S. “RapidPen: Fully Automated IP-to-Shell Penetration Testing.” 2025. arXiv:2502.16730
- Henke, J. “AutoPentest: Enhancing Vulnerability Management With Autonomous LLM Agents.” 2025. arXiv:2505.10321
- Pratama, D. et al. “CIPHER: Cybersecurity Intelligent Penetration-testing Helper.” Sensors 2024. arXiv:2408.11650
- Valencia, L. “Artificial Intelligence as the New Hacker: Developing Agents for Offensive Security.” 2024. arXiv:2406.07561
- Wang, L. et al. “CHECKMATE: Automated Penetration Testing with LLM Agents and Classical Planning.” 2025. arXiv:2512.11143
- Kong, H. et al. “VulnBot: Autonomous Penetration Testing for A Multi-Agent Collaborative Framework.” 2025. arXiv:2501.13411
Multi-Agent Systems:
- Udeshi, M. et al. “D-CIPHER: Dynamic Collaborative Intelligent Multi-Agent System for Offensive Security.” 2025. arXiv:2502.10931
- Luong, P. et al. “xOffense: An AI-driven Autonomous Penetration Testing Framework.” 2025. arXiv:2509.13021
- David, I. “MAPTA: Multi-Agent Penetration Testing AI for the Web.” 2024. arXiv:2508.20816
Benchmarks:
- Zhang, A. et al. “CyBench: A Framework for Evaluating Cybersecurity Capabilities.” ICLR 2025 Oral. arXiv:2408.08926
- Shao, M. et al. “NYU CTF Bench.” NeurIPS 2024. arXiv:2406.05590
- Zhu, Y. et al. “CVE-Bench.” ICML 2025 Spotlight. arXiv:2503.17332
- Gioacchini, L. et al. “AutoPenBench: Benchmarking Generative Agents for Penetration Testing.” 2024. arXiv:2410.03225
- Yang, R. et al. “PentestEval: Benchmarking LLM-based Penetration Testing.” 2025. arXiv:2512.14233
Real-World Impact:
- Google Project Zero & DeepMind. “From Naptime to Big Sleep.” 2024. Blog
- Lin, J. et al. “ARTEMIS: Comparing AI Agents to Cybersecurity Professionals.” 2025. arXiv:2512.09882
- Abramovich, T. et al. “EnIGMA: Interactive Tools Substantially Assist LM Agents.” ICML 2025. arXiv:2409.16165
DARPA AIxCC:
- Zhang, C. et al. “SoK: DARPA’s AI Cyber Challenge (AIxCC).” 2026. arXiv:2602.07666
Industry Reports:
- HackerOne. “2025 Hacker-Powered Security Report.” hackerone.com
- Anthropic. “Claude Mythos Preview & Project Glasswing.” April 2026. anthropic.com/glasswing
- Gartner. “Market Guide for Adversarial Exposure Validation.” 2025-2026.
- Straits Research. “Penetration Testing Market Report.” 2025.
FAQ#
Answers to the most common questions about AI pentesting agents.