
OpenAI Guardrails is an MIT-licensed Python library that provides a drop-in safety wrapper for the OpenAI Python client, adding automatic input/output validation with a tripwire mechanism that immediately halts agent execution when a violation is detected. It is listed in the AI security category.
The library is MIT licensed and maintained by OpenAI. The latest release is v0.2.1 (December 2025). It integrates directly with the OpenAI Agents SDK via the GuardrailAgent component for native safety enforcement in agentic workflows.
OpenAI Guardrails is distinct from the guardrails feature built into the Agents SDK — this library provides a broader set of configurable safety controls that can wrap any OpenAI API call, not just agent interactions.
What is OpenAI Guardrails?
OpenAI Guardrails sits between your application and the OpenAI API, intercepting requests and responses to run safety checks. The library uses a tripwire mechanism: when a guardrail detects a violation, it immediately raises an exception that halts execution, preventing unsafe content from being processed or returned.
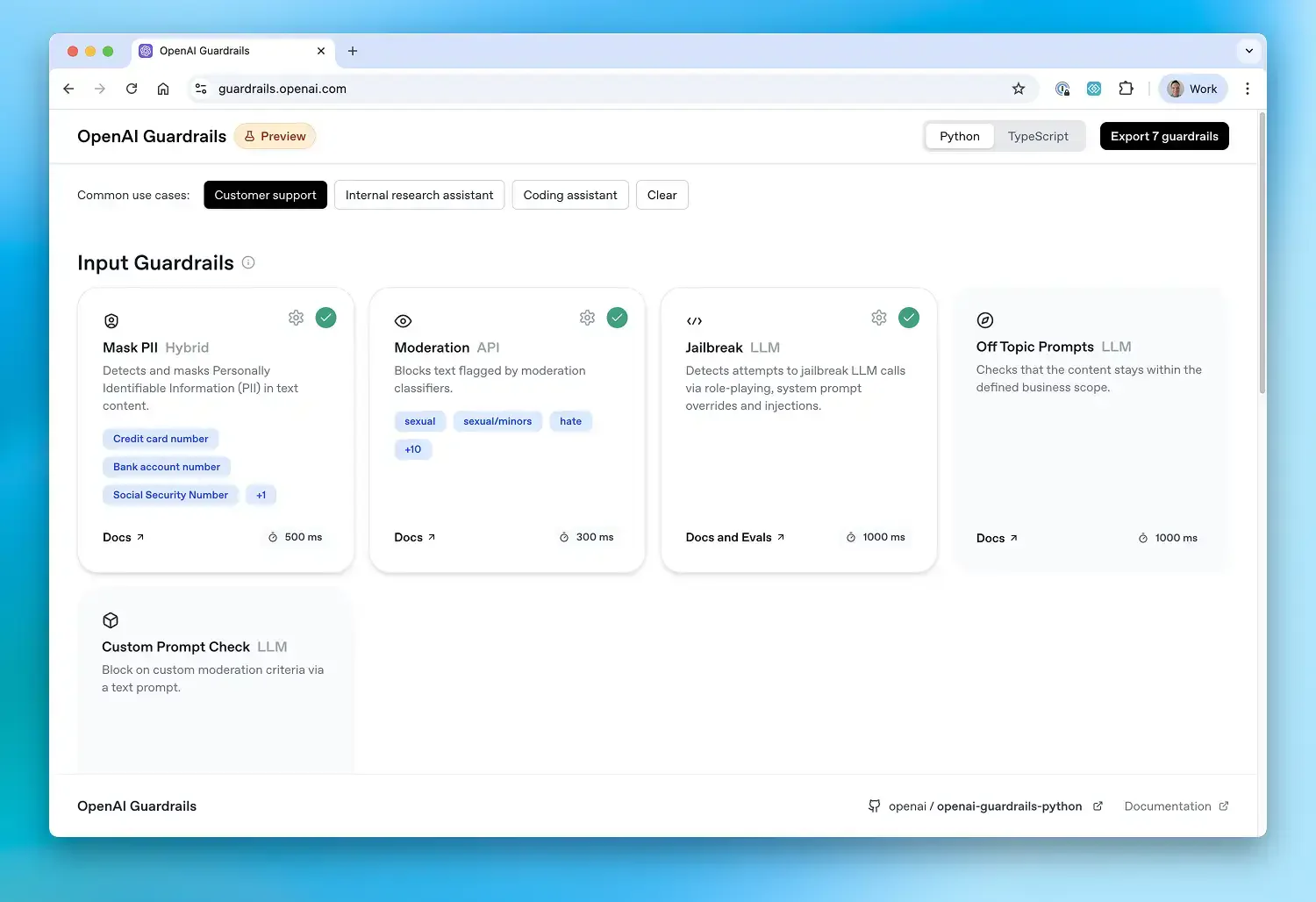
Three types of guardrails are supported. Input guardrails validate user prompts before the agent processes them.
Output guardrails validate agent responses before they reach users. Tool guardrails wrap function calls, validating both the arguments going in and the results coming out.
Built-in guardrails cover the most common safety requirements: content moderation, PII detection (via Microsoft’s Presidio), jailbreak detection, hallucination detection, URL filtering, NSFW content filtering, and off-topic detection. Custom guardrails can be added for domain-specific requirements.
The Guardrails Wizard provides a no-code configuration interface for building validation pipelines visually without writing JSON by hand.
What are OpenAI Guardrails’s key features?
| Feature | Details |
|---|---|
| Architecture | Drop-in wrapper for OpenAI Python client |
| Input Guardrails | Validate user prompts before agent execution; run only for the first agent in a chain |
| Output Guardrails | Validate agent responses; run only for the agent producing final output |
| Tool Guardrails | Wrap function tools to validate calls before and after execution |
| Tripwire | Immediate exception on violation, halting agent execution |
| Execution Modes | Parallel (lower latency) or blocking (zero token waste) |
| Built-in Checks | Moderation, PII detection, jailbreak, hallucination, URL filtering, NSFW, off-topic |
| PII Detection | Microsoft Presidio integration for local PII scanning |
| Custom Guardrails | Define custom checks with configurable thresholds |
| Configuration | JSON-based guardrail configuration or visual Guardrails Wizard |
| Evaluation | Built-in framework for benchmarking guardrail performance on labeled datasets |
| License | MIT |
Input guardrails
Input guardrails run on the user’s initial input before the agent begins processing. They are the first line of defense, catching jailbreak attempts, PII in prompts, off-topic requests, and content policy violations before any tokens are consumed.
One important detail: input guardrails run only for the first agent in a chain. In multi-agent workflows with handoffs, subsequent agents don’t re-run input guardrails on the original user message. For full coverage in orchestrated systems, use tool guardrails on individual function calls.
Input guardrails support two execution strategies. In parallel mode (the default), the guardrail runs concurrently with the agent for lower latency, but the agent may consume some tokens before a tripwire fires. In blocking mode, the guardrail must complete before the agent starts, preventing any token consumption on violations.
Output guardrails
Output guardrails validate the agent’s final response before it reaches the user. They catch hallucinated content, sensitive data in responses, toxic language, and policy violations in generated text.
Output guardrails run only for the agent that produces the final output in a multi-agent chain. They always execute after agent completion and do not support parallel execution — by definition, they need the complete response to validate.
Tool guardrails
Tool guardrails matter most for agentic applications where function calls have real-world consequences. They wrap function tools (decorated with @function_tool) to validate both the arguments going into the function and the results coming out.
Input tool guardrails can prevent execution entirely, replace the output with a safe default, or raise a tripwire. Output tool guardrails can replace results or raise tripwires. This is the mechanism for preventing agents from making unauthorized API calls, executing dangerous operations, or returning sensitive data from tool executions.

How do I get started with OpenAI Guardrails?
pip install openai-guardrails. Requires Python 3.9+ and an OpenAI API key for model-based guardrail checks.How much does OpenAI Guardrails cost?
OpenAI Guardrails is free and open-source under the MIT license. The library itself has no list price.
The cost driver is OpenAI API usage. Several built-in guardrails — moderation, hallucination checks, jailbreak classification — call the OpenAI API to make their decisions, so each guardrail invocation incurs standard OpenAI token charges. PII detection runs locally via Microsoft Presidio with no per-call fee.
The official documentation and GitHub repository cover the open-source distribution, including the Guardrails Wizard for visual configuration. There is no separate paid tier or sales-gated commercial edition; this is a community project maintained by OpenAI.
For broader pricing context across the AI security category, see the AI security tools hub. For a managed alternative, Lakera Guard offers a paid SaaS API.
When to use OpenAI Guardrails
OpenAI Guardrails fits teams building applications on the OpenAI platform that need configurable safety controls without building custom validation infrastructure. The drop-in wrapper approach means existing applications can add guardrails with minimal code changes.
The tool guardrails feature matters most for agentic applications. When AI agents can call functions that transfer money, send emails, query databases, or modify records, validating those calls before execution is critical. The tripwire mechanism blocks a flagged tool call immediately, not just logs it.
For teams already using the OpenAI Agents SDK, the native GuardrailAgent integration is the most natural fit. The guardrails become part of the agent architecture rather than external middleware.
What are alternatives to OpenAI Guardrails?
OpenAI Guardrails is one of several open-source guardrail libraries; the right alternative depends on your provider stack and validator needs. The closest substitutes:
- Guardrails AI — provider-agnostic Python framework with a larger validator library (Guardrails Hub) and re-prompting capabilities. A fit when you need OpenAI, Anthropic, and Cohere coverage in the same pipeline.
- NeMo Guardrails — NVIDIA’s open-source toolkit with five rail types and the Colang DSL for multi-turn dialog flow control. A fit when conversational dialog management matters as much as input/output filtering.
- LLM Guard — open-source Python library with 15 input scanners and 20 output scanners, MIT licensed. A fit when you want a thicker scanner library and provider-neutral self-hosting.
- Lakera Guard — commercial managed API (Check Point company) with sub-50ms latency. A fit when you prefer a managed SaaS over self-hosted code, and want classification across 100+ languages.
For comprehensive AI evaluation and observability, look at Galileo AI . For testing-first red teaming, see Promptfoo or Garak . For the wider AI security landscape, see the AI security tools hub.