
Giskard is an open-source Python library for automated AI testing that detects security vulnerabilities, bias, and quality issues in LLMs, RAG applications, and traditional ML models.
Its autonomous red teaming agents run multi-turn attacks across 40+ probes, while the RAGET toolkit auto-generates test cases for RAG evaluation. Giskard has 5,200+ GitHub stars and is listed in the AI security category.
The company was founded in 2021 in Paris by Alex Combessie and Jean-Marie John-Mathews. The name comes from R. Giskard Reventlov, a positronic robot in Isaac Asimov’s novels.
Giskard offers a free open-source SDK (Apache 2.0) and a commercial Enterprise Hub for team collaboration and continuous testing. Enterprises like AXA, BNP Paribas, and Michelin use the platform.

Overview
Most AI security tools focus on either LLM-specific threats or traditional ML quality issues. Giskard handles both in a single framework: prompt injection, hallucinations, and jailbreaks on one side; bias, data leakage, and performance degradation on the other. Same library, same API.
For LLM and RAG applications, Giskard deploys autonomous red teaming agents that run multi-turn attacks across 40+ probes. These agents adapt their strategies during the conversation.
If one approach gets blocked, they escalate or pivot to a different technique. Static single-prompt testing misses these multi-turn attack paths.
For traditional ML models, Giskard automatically scans for performance issues, bias across protected groups, data leakage, and robustness problems. It works with scikit-learn, XGBoost, CatBoost, LightGBM, and other popular frameworks.
What are Giskard’s key features?
| Feature | Details |
|---|---|
| GitHub stats | 5.2k stars, Apache 2.0 (OSS), commercial Hub |
| LLM probes | 40+ covering security and business failures |
| Red teaming | Autonomous multi-turn agents with adaptive strategies |
| RAG evaluation | RAGET toolkit with auto-generated test cases |
| ML model support | scikit-learn, XGBoost, CatBoost, LightGBM, TensorFlow, PyTorch |
| Integrations | MLflow, Weights & Biases, Hugging Face, CI/CD pipelines |
| Python support | 3.9 to 3.12 |
| Enterprise | Giskard Hub for collaboration and continuous testing |
| Founded | 2021, Paris |
| Backed by | Elaia, Bessemer Venture Partners |
LLM vulnerability scanning
The LLM scan is the core feature. When I ran it against a customer support chatbot, it automatically generated adversarial prompts designed to trigger failures across two categories:
Security failures:
- Prompt injection — attempts to override system instructions
- Harmful content generation — probes for toxic or dangerous outputs
- PII disclosure — tries to extract personal information from the model
- Stereotypes and discrimination — tests for biased responses across demographic groups
Business failures:
- Hallucination — generates questions where the model should admit uncertainty but instead fabricates answers
- Denial of service — identifies cases where the model refuses to answer legitimate questions
- Off-topic responses — tests whether the model stays within its intended scope
- Inconsistency — checks for contradictory answers to semantically similar questions
The scanner uses autonomous agents that conduct multi-turn conversations, escalating attack intensity when initial probes are blocked. This catches vulnerabilities that single-turn testing misses.
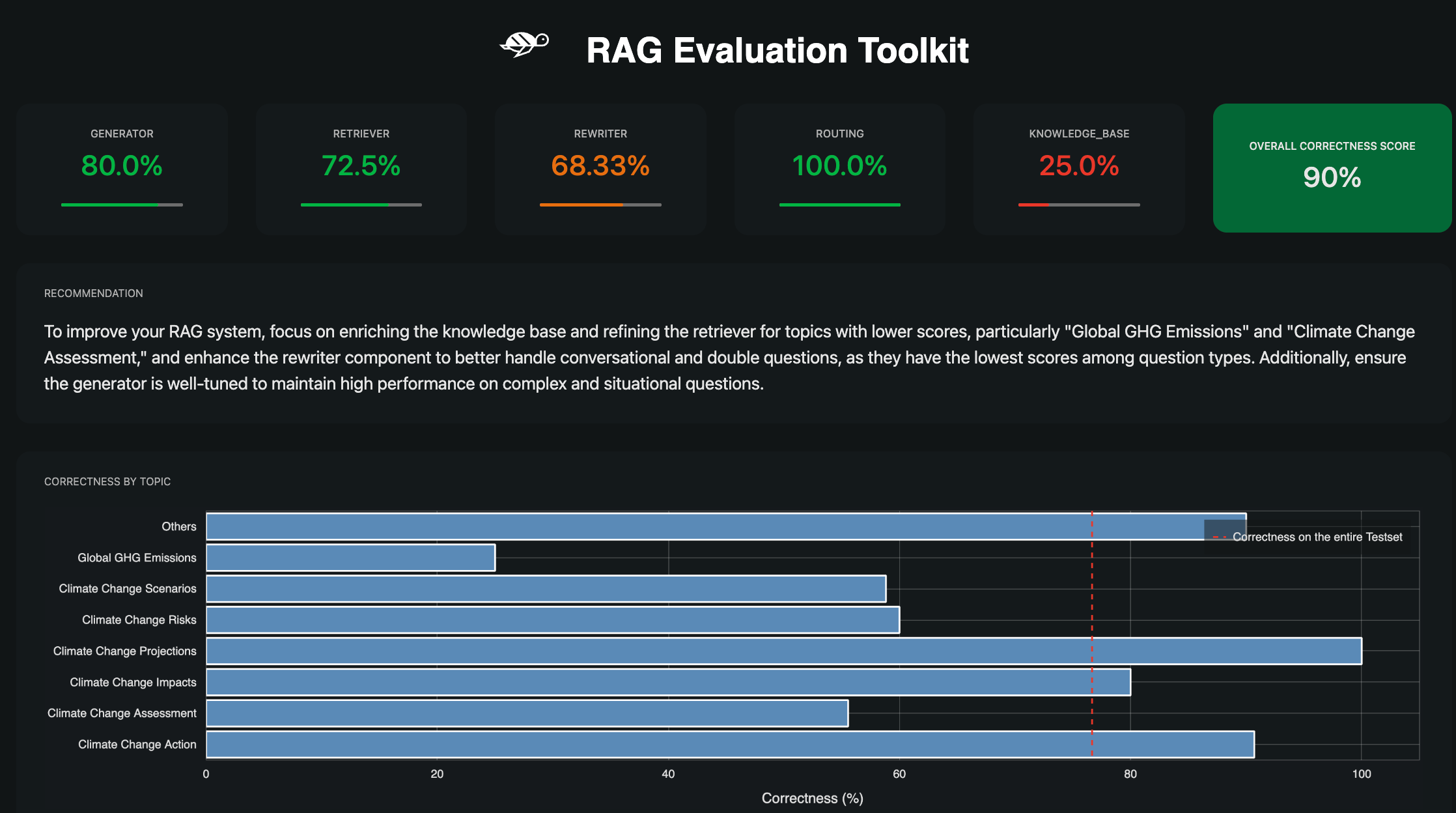
RAGET — RAG Evaluation Toolkit
RAGET tackles one of the hardest parts of RAG testing: creating realistic test cases. Instead of manually writing questions, RAGET reads your knowledge base and generates:
- Questions at different difficulty levels
- Reference answers derived from the source documents
- Reference context chunks for retrieval accuracy evaluation
It then evaluates your RAG pipeline on retrieval accuracy (did it find the right chunks?), context relevance (are the retrieved chunks actually useful?), answer correctness (does the response match the reference?), and hallucination rate (did the model make things up?).
Traditional ML model testing
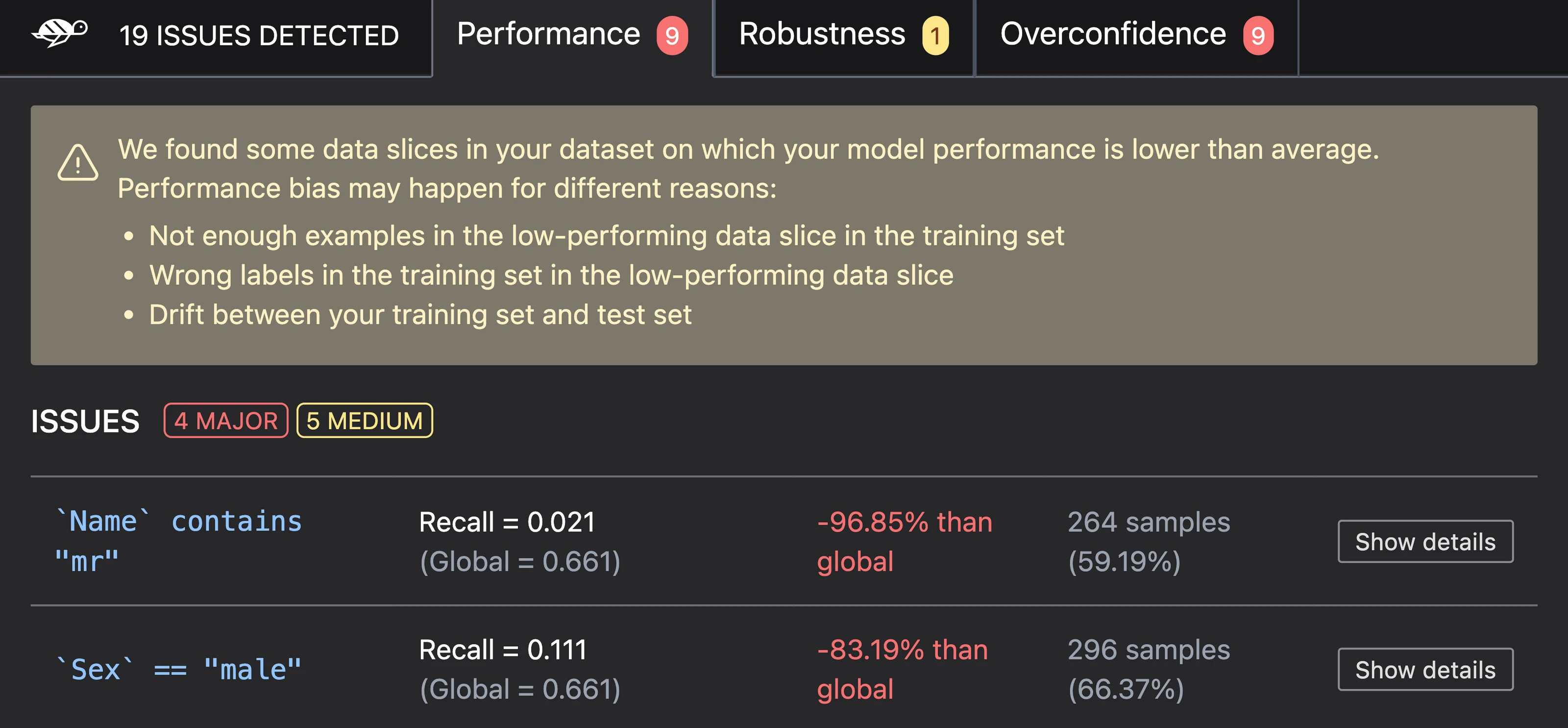
Beyond LLMs, Giskard tests tabular ML models for:
- Performance issues — Identifies slices of data where model accuracy drops significantly
- Bias — Detects differential performance across protected groups (gender, race, age)
- Data leakage — Finds features that inadvertently leak target information
- Robustness — Tests model behavior under input perturbations
The ML testing module supports classification, regression, and ranking models. It wraps models from scikit-learn, XGBoost, CatBoost, LightGBM, TensorFlow, and PyTorch.
Giskard Hub (Enterprise)
The open-source SDK runs locally and handles individual scans. Giskard Hub adds features for teams:
- Team collaboration — Share scan results, annotate findings, track remediation
- Continuous red teaming — Schedule recurring scans to catch regressions after model updates
- Version comparison — Compare scan results across model versions to track improvement
- Centralized dashboard — Aggregate results across multiple models and applications
What does Giskard integrate with?
How do I get started with Giskard?
pip install "giskard[llm]" for LLM testing or pip install giskard for traditional ML model testing. Requires Python 3.9+.export OPENAI_API_KEY="sk-..." (or Anthropic, Azure, etc.). Giskard uses this to power its red teaming agents.giskard.scan(model=your_model, dataset=your_dataset) to start the automated vulnerability scan. Review the HTML report for detected issues.LLM scan example
import giskard
# Define your LLM wrapper
def my_chatbot(question: str) -> str:
# Call your LLM endpoint here
return response
# Wrap the model
model = giskard.Model(
my_chatbot,
model_type="text_generation",
name="Customer Support Bot",
description="Answers questions about our products"
)
# Run the scan
results = giskard.scan(model)
results # Displays HTML report in Jupyter
RAGET example
from giskard.rag import KnowledgeBase, generate_testset
# Load your knowledge base
knowledge_base = KnowledgeBase.from_pandas(df)
# Generate test cases automatically
testset = generate_testset(
knowledge_base,
num_questions=100,
language="en"
)
# Evaluate your RAG pipeline
report = testset.evaluate(my_rag_pipeline)
When should you use Giskard?
- Pre-deployment LLM security audit — Run the vulnerability scanner before launching a customer-facing chatbot to check for prompt injection, hallucination, and harmful content risks.
- RAG quality assurance — Use RAGET to automatically generate test suites from your knowledge base and measure retrieval accuracy, hallucination rates, and answer quality.
- Bias compliance testing — Scan ML models for differential performance across demographic groups to meet fairness requirements before production deployment.
- Continuous monitoring — Schedule recurring scans via Giskard Hub to detect new vulnerabilities that emerge after model updates or knowledge base changes.
- Model comparison — Evaluate multiple LLM providers or model versions against the same test suite to pick the best option based on actual results.
Strengths & Limitations
Strengths:
- Covers both LLM security and traditional ML quality in one framework, which is uncommon
- RAGET automates RAG test case generation, cutting out hours of manual work
- Multi-turn adaptive red teaming catches vulnerabilities that static single-prompt tools miss
- Active open-source community with 5.2k GitHub stars and enterprise backing
- Integrates with MLflow, Weights & Biases, and CI/CD pipelines
Limitations:
- Requires an LLM API key (OpenAI or similar) to power the red teaming agents — adds cost to scanning
- Enterprise Hub pricing is not publicly listed — contact sales required
- The open-source SDK handles individual scans but lacks the collaboration and scheduling features of the paid Hub
- Newer v3 rewrite is still maturing — some v2 features may not be fully ported yet
What are alternatives to Giskard?
Most LLM testing frameworks specialize in one slice of the problem. Giskard’s differentiator is covering both LLM applications and traditional ML models in the same library. Here is how the closest alternatives compare:
- Garak — A dedicated LLM vulnerability scanner with the widest probe library (50+ attack modules). Pick Garak when LLM-only coverage is enough and you want raw probe breadth over RAG evaluation or tabular ML support.
- DeepTeam — Structured LLM red teaming explicitly mapped to OWASP Top 10 for LLMs. Best when audit reports need a clean mapping to that framework rather than Giskard’s mixed security-and-quality categories.
- PyRIT — Microsoft’s open-source red teaming toolkit for generative AI. Good fit if you already run on Azure OpenAI and want a Microsoft-maintained option with first-class agentic attack scenarios.
- Promptfoo — A general LLM evaluation framework with red teaming as one capability. Choose Promptfoo when you need broad eval (regression, A/B prompt tests) and treat security as a sub-feature rather than the headline.
- ART (Adversarial Robustness Toolbox) — IBM-led library for evasion, poisoning, and extraction attacks against computer vision and tabular ML. Use ART when the threat model is adversarial inputs against classifiers, not LLM jailbreaks.
- NeMo Guardrails and LLM Guard — Runtime guardrail layers, not pre-deployment scanners. Pair these with Giskard rather than swap them in: Giskard tests the model offline, guardrails enforce policy at request time.
For a wider catalog, the AI security tools hub groups these by sub-category (red teaming, runtime guardrails, RAG evaluation).