
Galileo AI is an evaluation intelligence platform for generative AI applications and agents that turns offline evaluation metrics into production guardrails using purpose-built Luna-2 small language models. It is listed in the AI security category.
Cisco announced its intent to acquire Galileo on April 9, 2026 and completed the acquisition on May 22, 2026. Galileo is being folded into Cisco’s Splunk Observability portfolio.
Founded in San Francisco, Galileo raised $45M in Series B funding in 2024 led by Scale Venture Partners, with participation from Premji Invest, bringing total funding to $68M as of the 2024 Series B announcement.
The company reported 834% revenue growth since the beginning of 2024 and quadrupled its enterprise customer count, bringing on six Fortune 50 companies including Comcast and Twilio (vendor-reported figures from Galileo’s 2024 Series B announcement; verify the latest funding total on galileo.ai/about for any post-Series-B rounds).
Galileo’s core thesis, per the vendor’s published Luna-2 benchmarks, is that generic LLM-as-a-judge evaluators score below 70% F1 on many production evaluation tasks, and that purpose-built evaluation models can close that gap while keeping costs low enough to monitor 100% of production traffic.
What is Galileo AI?
Galileo takes a different approach from typical guardrail tools. Rather than just blocking or allowing individual requests, it builds an evaluation layer across the full AI lifecycle — from offline testing through production monitoring.
The platform centers on Luna-2, a family of small language models fine-tuned specifically for evaluation tasks. These models score AI outputs across 20+ metrics simultaneously, running at sub-200ms latency so they can operate as real-time guardrails without adding noticeable delay.
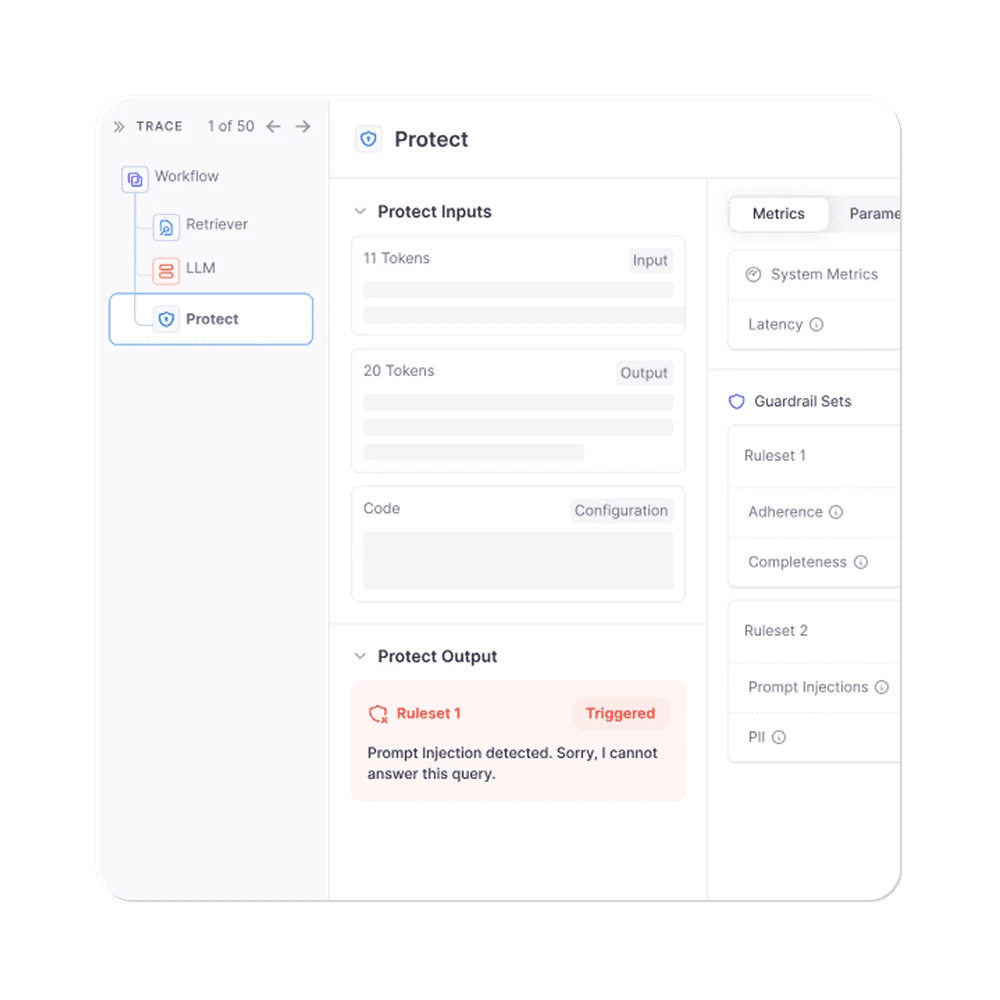
The evaluation-to-guardrail pipeline means teams can develop metrics during testing and deploy the same metrics as production safeguards. When a metric detects a violation — hallucination, prompt injection, PII leak, policy breach — the platform can block the response before it reaches the user.
What are Galileo AI’s key features?
| Feature | Details |
|---|---|
| Evaluation Metrics | 20+ built-in: context adherence, chunk utilization, hallucination, PII leak, prompt injection, bias, sexism, toxicity, and more |
| Luna-2 Models | Fine-tuned Llama 3B/8B variants with lightweight adapters |
| Latency | 152ms average; sub-200ms for 10-20 concurrent checks (Galileo-reported) |
| Accuracy | 0.95 AUROC across evaluation tasks (Galileo benchmark, not independently verified) |
| Context Window | 128k max tokens |
| Agentic Metrics | Tool error rate, tool selection quality, action advancement, action completion |
| Safety Metrics | PII leak, sexism, bias, prompt injection detection |
| Custom Evaluators | Build domain-specific metrics with the custom evaluator builder |
| MCP Support | Model Context Protocol server integration |
| Deployment | SaaS, Virtual Private Cloud, on-premises |
| CI/CD | Unit testing and pipeline integration for AI development workflows |
Luna-2 evaluation models
Luna-2 models are the engine behind Galileo’s evaluation capabilities. Built as fine-tuned versions of Llama models (3B and 8B parameter variants), they use lightweight adapters on a shared core architecture. This design lets Galileo scale across hundreds of metric types without requiring separate model instances for each one.
The models output normalized log-probabilities to determine metric scores, hosted on Galileo’s optimized inference engine. The distillation approach — converting expensive LLM-as-judge evaluators into compact Luna models — is what makes 100% traffic monitoring feasible at scale, since fine-tuned small models cost a fraction of GPT-3.5-class evaluators on equivalent throughput.
RAG evaluations
For retrieval-augmented generation applications, Galileo provides specialized metrics. Context adherence measures whether the model’s response stays faithful to retrieved context.
Chunk utilization tracks how effectively the model uses retrieved information. These metrics help catch hallucinations where the model invents information not present in the source material.
Agentic evaluations
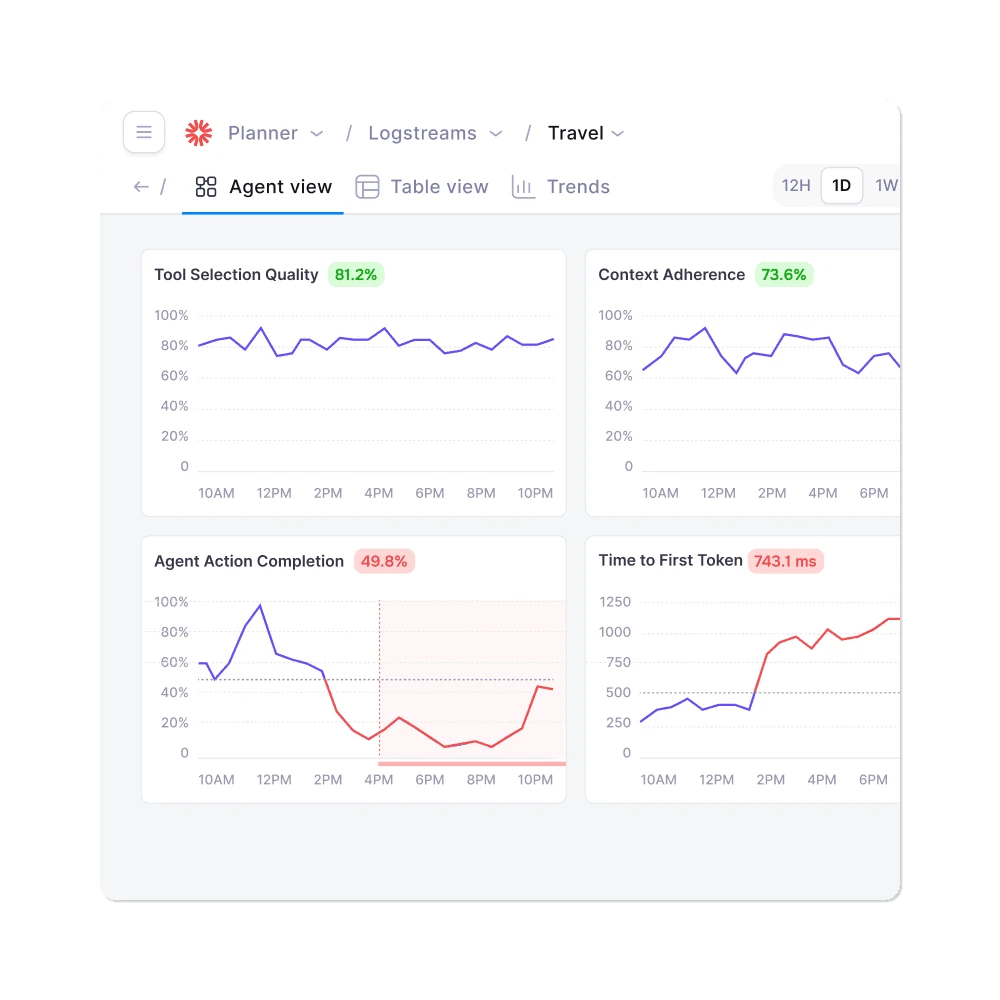
Galileo’s agent-specific metrics go beyond text quality. Tool error rate tracks how often agents fail at tool execution.
Tool selection quality measures whether the agent picks the right tool for the task. Action advancement and action completion metrics assess whether agents make meaningful progress toward their goals.
Distilled LLM-as-a-judge for OWASP and NIST coverage
The Luna-2 design replaces the traditional LLM-as-a-judge evaluation pattern — where a frontier model like GPT-4 grades each output — with distilled small models that hit similar accuracy at a fraction of the cost. That matters for security because per-request evaluation is no longer a budget question, and 100% traffic monitoring becomes the default.
The built-in metrics map onto OWASP Top 10 for LLM Applications categories: hallucination and chunk-utilization checks address LLM09 Misinformation; PII leak and context-adherence detectors address LLM02 Sensitive Information Disclosure; prompt injection and bias evaluators address LLM01 Prompt Injection and LLM05 Improper Output Handling.
For compliance, the same evaluation telemetry supports the NIST AI RMF Measure and Manage functions — every Luna-2 score is a structured audit record that can feed into AI governance reviews and EU AI Act high-risk system documentation.
How do I get started with Galileo AI?
When to use Galileo AI
Galileo fits teams that need systematic evaluation and monitoring for production AI systems, not just point-in-time testing. The Luna-2 models make it practical to evaluate 100% of traffic rather than sampling, which matters when even rare failures carry significant risk — healthcare recommendations, financial decisions, customer-facing agents handling sensitive data.
It is particularly relevant for organizations building agentic AI applications where tool selection errors or unauthorized actions have real-world consequences. Galileo’s agentic metrics catch these failure modes at the evaluation layer, before they reach tool execution.
Teams already using CI/CD for traditional software development can extend those workflows to AI pipelines, running evaluation suites on each model or prompt change.
For a broader overview of AI security risks and tools, see the AI security tools guide . For input/output-only guardrails without evaluation intelligence, consider LLM Guard or NeMo Guardrails .
For adversarial testing and red teaming, look at Garak or Promptfoo . For runtime data privacy protection in AI pipelines, see Protecto .
What are alternatives to Galileo AI?
Galileo’s Luna-2 cost economics are the editorial wedge for 100% traffic evaluation. If that price-per-token model is not the constraint, five alternatives cover overlapping ground.
Arize AI / Phoenix is the closest open-source observability sibling. Arize Phoenix is free and self-hosted, with strong tracing and evaluation tooling — the right choice when an in-house team wants to avoid vendor lock-in and is comfortable running its own LLM-as-a-judge evaluators.
Langfuse (langfuse.com) is the leading open-source LLM evaluation and tracing platform. Langfuse is the better fit when the priority is flexible self-hosted observability and OpenTelemetry-native traces rather than purpose-built evaluation models.
Arthur AI competes on multi-model breadth — it monitors LLMs alongside tabular, NLP, and computer vision models with bias detection and explainability. Arthur is the better pick when the same team manages both classical ML and LLM workloads.
LLM Guard is the lightweight runtime alternative. It is the right choice when only input/output filtering is needed and full evaluation intelligence (RAG quality, agent metrics) is overkill.
Helicone (helicone.ai) is a developer-first LLM logging and gateway alternative. Helicone fits engineering teams that want fast OpenAI-style logging plus simple eval add-ons rather than enterprise evaluation governance.
For runtime data privacy in AI pipelines specifically, see Protecto ; for broader AI security context, see the AI security tools category.