Adversarial Robustness Toolbox (ART) is an open-source Python library from IBM Research for testing and improving the security of machine learning models against adversarial attacks. ART implements 55+ attack methods and 30+ defense mechanisms across four threat categories: evasion, poisoning, extraction, and inference.
It has 5,900+ GitHub stars and is listed in the AI security category.
IBM started the project in 2018 and donated it to the Linux Foundation AI & Data Foundation (LF AI & Data), where it became a graduated project — the highest maturity level in the foundation. The current version is 1.20.1, released in July 2025.
ART is different from most AI security tools because it focuses on traditional ML model robustness rather than LLM-specific threats.
If you work with image classifiers, object detectors, speech recognition models, or tabular ML pipelines, ART is the go-to library for testing adversarial resilience.
Overview
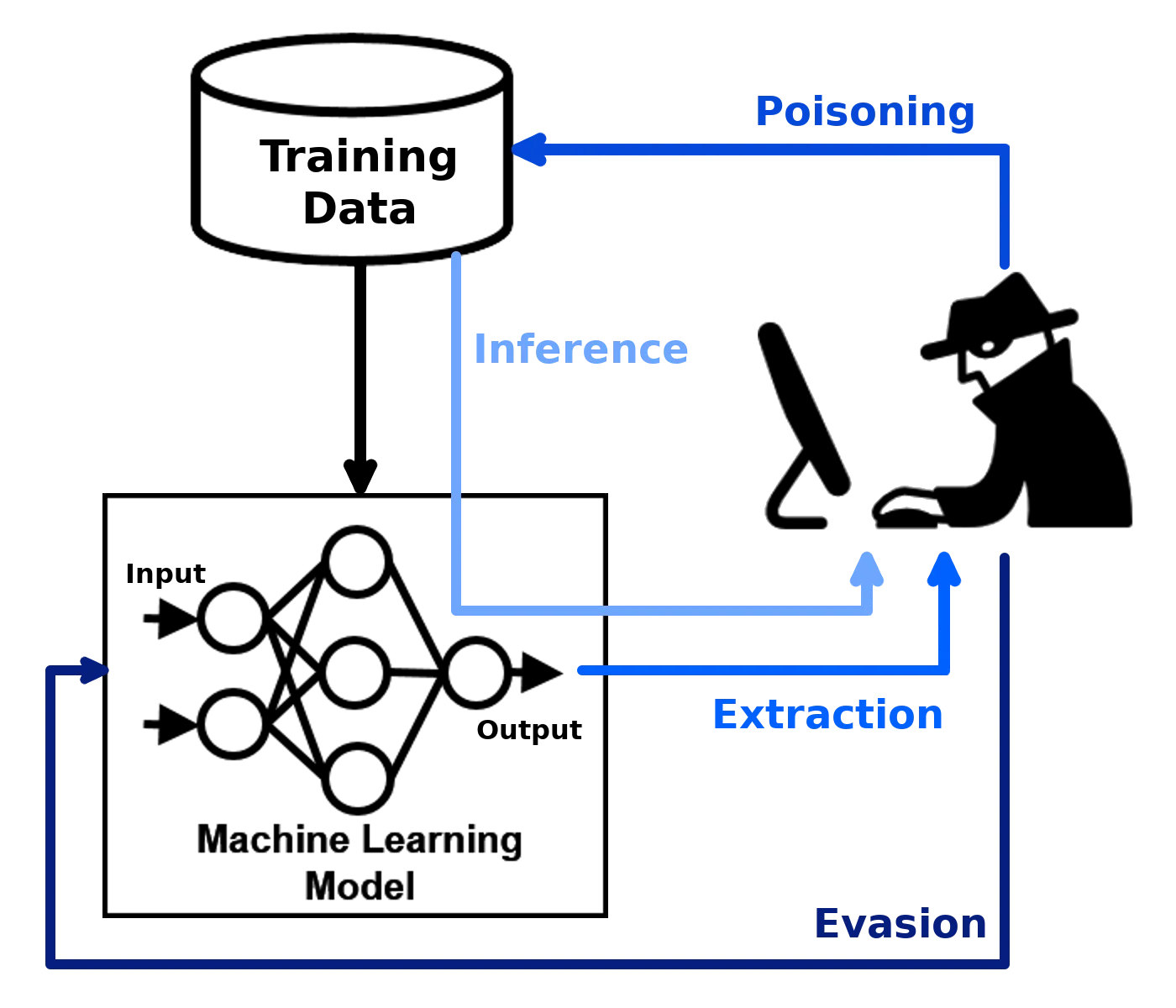
ART addresses four categories of adversarial threats against machine learning systems:
- Evasion — Modifying inputs at inference time to cause misclassification (adversarial examples)
- Poisoning — Manipulating training data to compromise model behavior
- Extraction — Stealing a model’s functionality through queries
- Inference — Attacking the privacy of training data (membership inference, model inversion)
The library implements 55+ attack methods and 30+ defense mechanisms across these categories.
I reviewed ART’s documented behavior with PyTorch image classifiers, and the API is consistent regardless of which framework or attack type you use — you wrap your model, pick an attack or defense, and run it.
ART supports all popular ML frameworks: TensorFlow, Keras, PyTorch, scikit-learn, XGBoost, LightGBM, CatBoost, and GPy.
It handles images, tabular data, audio, and video inputs, covering tasks from classification and object detection to speech recognition and generative models.
What are Adversarial Robustness Toolbox (ART)’s key features?
| Feature | Details |
|---|---|
| Current version | 1.20.1 (July 2025) |
| GitHub stats | 5.9k stars, MIT license |
| Attack categories | Evasion, poisoning, extraction, inference |
| Defense modules | Preprocessor, postprocessor, trainer, transformer, detector |
| ML frameworks | TensorFlow, Keras, PyTorch, scikit-learn, XGBoost, LightGBM, CatBoost, GPy |
| Data types | Images, tables, audio, video |
| ML tasks | Classification, object detection, speech recognition, generation, certification |
| Installation | pip, Docker |
| Python support | 3.10+ |
| Governance | LF AI & Data Foundation (graduated project) |
Evasion attacks
Evasion attacks modify inputs at inference time to fool a trained model. ART implements the most widely studied attack methods in adversarial ML research:
- FGSM (Fast Gradient Sign Method) — Single-step gradient-based perturbation. Fast but less effective against robust models.
- PGD (Projected Gradient Descent) — Iterative version of FGSM. The standard benchmark for adversarial robustness evaluation.
- C&W (Carlini & Wagner) — Optimization-based attack that finds minimal perturbations. Slower but more effective.
- DeepFool — Computes the minimal perturbation to cross the decision boundary.
- AutoAttack — Ensemble of attacks for reliable robustness evaluation.
These attacks work across image classifiers, object detectors, and speech recognition models. ART handles the framework-specific gradient computation behind the scenes.
Poisoning attacks
Poisoning attacks target the training phase. ART supports backdoor attacks (inserting triggers into training data) and clean-label attacks (subtly modifying legitimate training examples to shift model behavior).
These are harder to detect because the training data may look normal to human reviewers. ART’s poisoning defense modules help detect and mitigate these attacks before they compromise a production model.
Extraction and inference attacks
Model extraction attacks like CopycatCNN and KnockoffNets reconstruct a target model’s behavior using only query access. This threatens proprietary models served via APIs — an attacker can clone the model’s functionality without access to weights or training data.
Inference attacks target data privacy. Membership inference determines whether a specific data point was in the training set.
Model inversion reconstructs training examples from model outputs. Attribute inference infers sensitive attributes about training data subjects.
Defense mechanisms
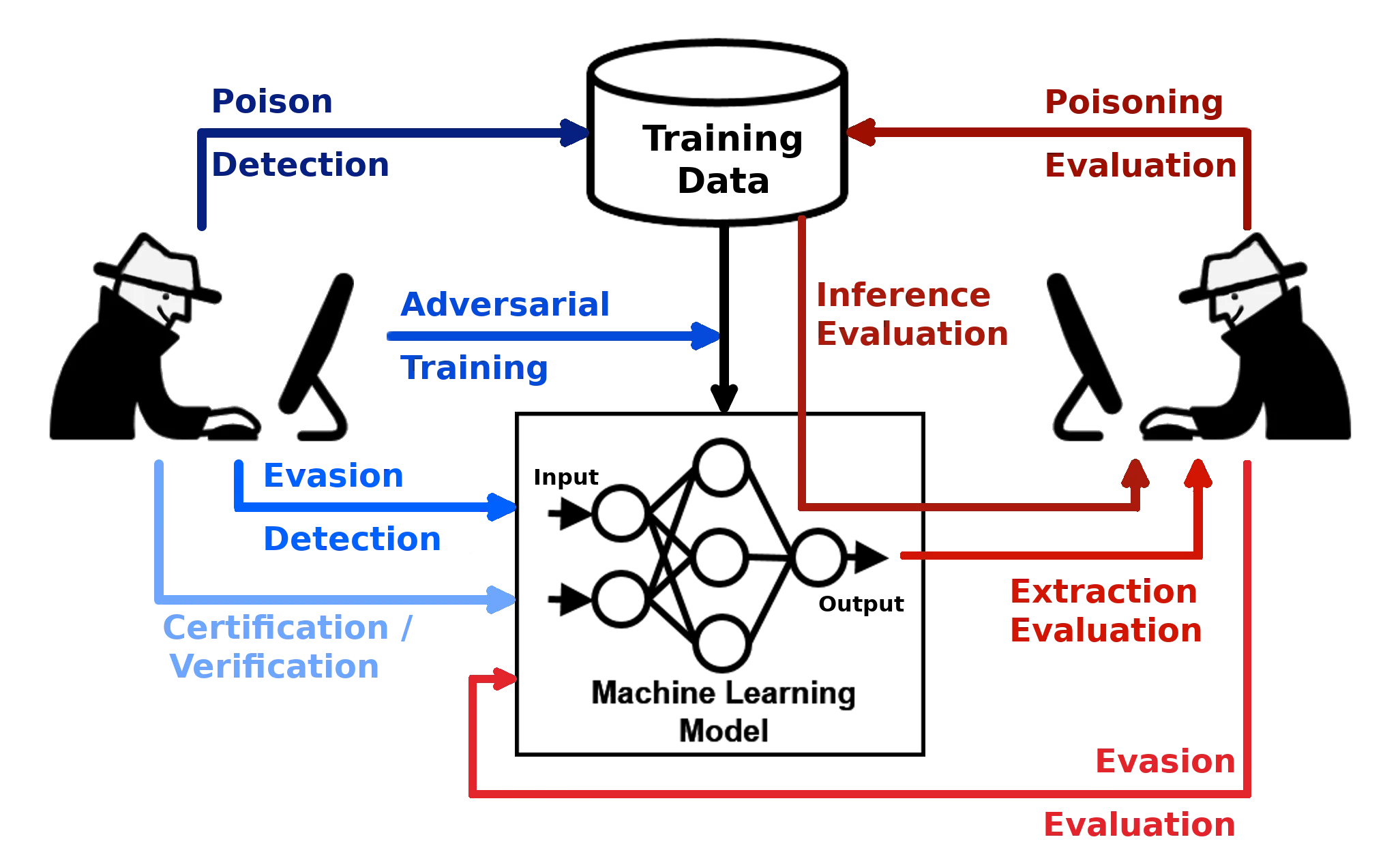
ART’s defenses fall into five categories:
- Preprocessors — Transform inputs before they reach the model (spatial smoothing, JPEG compression, feature squeezing, thermometer encoding)
- Postprocessors — Modify model outputs to reduce information leakage
- Trainers — Adversarial training methods that incorporate adversarial examples during model training
- Transformers — Model modification techniques for robustness
- Detectors — Identify adversarial inputs at inference time
Note: ART implements attacks and defenses from peer-reviewed ML security papers. The library includes over 100 Jupyter notebooks demonstrating individual techniques, making it useful for both research and practical security testing.
GREAT Score and YOLO support
Version 1.20.0 introduced the GREAT Score (Global Robustness Evaluation of Adversarial Perturbation using Generative Models), which uses generative AI to measure model robustness without requiring manual perturbation design.
The same release added support for YOLO v8+ object detection models.
Supported Frameworks
How do I get started with Adversarial Robustness Toolbox (ART)?
pip install adversarial-robustness-toolbox. For specific frameworks, install their dependencies separately (e.g., pip install torch torchvision for PyTorch).art.estimators.classification.PyTorchClassifier (or TensorFlowV2Classifier, SklearnClassifier, etc.) to wrap your trained model. ART needs the wrapper to compute gradients and manage inputs.art.attacks.evasion.FastGradientMethod), configure parameters like epsilon, and call attack.generate(x_test) to create adversarial examples.art.defences.preprocessor.SpatialSmoothing) and wrap it around your estimator. Test the defended model against the same attacks to measure robustness improvement.Basic usage example
from art.estimators.classification import PyTorchClassifier
from art.attacks.evasion import FastGradientMethod
from art.defences.preprocessor import SpatialSmoothing
# Wrap your PyTorch model
classifier = PyTorchClassifier(
model=model,
loss=criterion,
optimizer=optimizer,
input_shape=(3, 32, 32),
nb_classes=10
)
# Generate adversarial examples
attack = FastGradientMethod(estimator=classifier, eps=0.3)
x_adversarial = attack.generate(x=x_test)
# Evaluate accuracy drop
predictions = classifier.predict(x_adversarial)
Docker support
ART provides Docker images for reproducible environments:
docker pull adversarialrobustnesstoolbox/art:latest
docker run -it adversarialrobustnesstoolbox/art:latest
When should you use Adversarial Robustness Toolbox (ART)?
- Model robustness testing — Run standardized attack suites (PGD, AutoAttack) against image classifiers before deployment to quantify adversarial vulnerability.
- Adversarial training — Use ART’s trainer module to augment training data with adversarial examples, producing models that resist perturbation attacks.
- Privacy assessment — Run membership inference and model inversion attacks to evaluate whether a model leaks sensitive information about its training data.
- Supply chain model security — Test third-party or pre-trained models for backdoor poisoning before integrating them into production pipelines.
- Research and benchmarking — Reproduce published adversarial ML results and compare new defense methods against standard attack benchmarks.
Strengths & Limitations
Strengths:
- Widest coverage of adversarial ML techniques in a single library (55+ attacks, 30+ defenses)
- Framework-agnostic design supports all major ML libraries through a unified API
- Graduated LF AI & Data project with IBM Research backing and active maintenance
- Extensive Jupyter notebook collection (100+) for learning and experimentation
- Covers the full adversarial ML workflow: attacks, defenses, detection, and certification
Limitations:
- Focused on traditional ML models — limited coverage for LLM-specific threats like prompt injection or jailbreaks
- Some advanced attacks have high computational requirements, especially on large models
- Documentation, while extensive, can be fragmented across the wiki, ReadTheDocs, and notebooks
- Requires ML framework expertise to configure model wrappers correctly
Pro tip: ML engineers and security researchers who need to evaluate and improve the adversarial robustness of computer vision, speech, or tabular machine learning models using standardized attack and defense methods.
ART alternatives
ART is the most comprehensive adversarial-ML library for traditional models. The closest alternatives split by what surface they prioritize:
- Garak — Probe-based vulnerability scanner for LLMs covering prompt injection, jailbreaks, and hallucination. A fit when the target is language models rather than computer vision or tabular ML.
- DeepTeam — OWASP LLM Top 10–mapped red teaming for language models. A fit when the requirement is LLM red teaming with explicit framework alignment.
- Giskard — Hybrid testing framework covering both LLMs and traditional ML models. A fit when a single tool needs to span both surfaces but with shallower coverage on classic adversarial attacks than ART.
- CleverHans — Older Python research library for adversarial-example generation. A fit for academic reproducibility against published attack baselines, though it is no longer actively maintained at ART’s pace.
- Foolbox — Python library focused on fast adversarial-example generation across PyTorch, TensorFlow, and JAX. A fit when minimal-perturbation evaluation is the priority and you want a smaller, more focused dependency.
For runtime guardrails on language models, consider NeMo Guardrails or LLM Guard .
For a broader overview of the AI security landscape, see the AI security tools guide .